
ネット広告の新定番「RSA」の予測に成功した!(?) できるだけわかりやすく解説
- はじめに
- RSAってどんなもの
- オッカムの剃刀をぶん回した
- 生のCTRには扱いづらさがある
- 前回のハンドクラフト特徴量の再登場
- さあ、実験だ!
- その結果は?
- わざわざ特徴量をつくる?ファインチューニングで良くない?
- 逆に、ハンドクラフト特徴量にはどんな利点があるの?
- 「成功」は多面的なものである
はじめに
こんにちは、株式会社オプトAIソリューション開発部所属の Melvin Charles DY (メルヴィン チャールス ディ)です。
テキスト広告の効果予測について去年も論文を学会にてポスター発表しました。学会の後、発表内容に関する記事も執筆しています。気になる方は是非、読んでください。
上記の記事でも触れましたが、去年2022年の6月から新規の拡張テキスト広告(Expanded Text Ads, 「ETA」 )が事前の予告通り作れなくなりました。やっと良さそうなものできたのに使えなくなったことに、虚無感に襲われなかったと言えば嘘になります(苦笑)。でも次に進む道が明確だったのでその勢いで次のプロジェクトに取り掛かりました。(余談:ChatGPTとの組み合わせによってETAのCTR予測器が思わぬ形で活用されるとは、このときは知る由もありませんでした)その次のプロジェクトは、レスポンシブ検索広告(Responsive Search Ads, 以降「RSA」)のCTR予測でした。
結果として、RSAのCTR予測に成功しましたし、論文も出させていただきました。論文の本文は今年はJSAIの国際セッションで口頭発表しました。今年の人工知能学会全国大会論文集にて公開されましたので、興味があればぜひご一読ください。なお、論文も発表も英語で行いましたので、この記事のために引用した表や図は英語になっています。
この記事は基本的に論文の内容と一緒ですが、その研究の本筋にできるだけ話を絞って、わかりやすく解説していきたいと思います。
RSAってどんなもの
先述もしましたが、RSAは日本語で言うと「レスポンシブ検索広告」です。その名の通り、RSAは検索に連動して動的に反応する(「レスポンシブ」)広告です。今回はGoogle社のRSAに絞って研究を行いましたが、似たようなものが他の広告プラットフォームにも存在します。
簡単に言うと、エンドユーザーが検索をする際、入力されたキーワードに合わせて事前に登録された見出しと説明文から数個が自動的に選出され、それを組み合わせた結果が検索結果と一緒に表示される広告として表示されます。一度に見出し最大3つ、説明文最大2つが使われます。公式ヘルプページには「デバイスの幅に適応した柔軟な広告が作成されるため…」と記載されています。明記されていませんが、デバイスの画面幅と広告の文字数によって表示されるアセットの数が変わると察せられます。
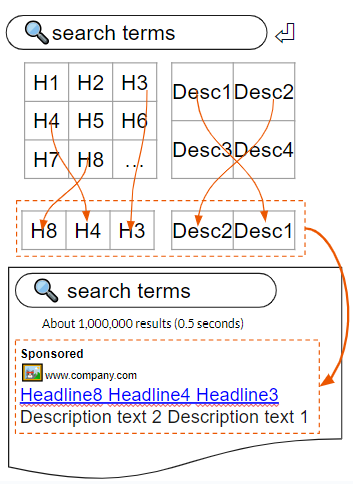
アセットごとに、そのアセットがどの位置に出現するかを固定できます。見出しの場合、3つの位置があり、説明文には2つの位置があります。免責条項や重要注意点を絶対出したい場合には役に立つ機能ですが、組み合わせの自由度を大きく減少させてしまうため、あまり推奨されていません。法律的に記載されるべき内容だけを固定表示して、訴求の部分はできるだけ検索に合わせられるようにしておくのがRSAにおける定石です。
もう少し細かい説明は公式ヘルプページに書いてあるので、興味ある方は是非見てみてください。
前の定番形式であった拡張テキスト広告(Expanded Text Ads, ETA)と違って、RSAはダイナミックに表示内容が変わります。そのおかげで、検索されたキーワードにもっとも関連しているアセット(見出しと説明文の総称)が優先されて表示されるため、クリックされる可能性は上がります。
そのような広告形式のCTRを予測しようと思った場合、最終的に表示されたアセットの組み合わせと、それがクリックされたかどうかというデータがあれば簡単にできます。ところが、そのデータはありません。
RSAのCTR予測という課題に手をかけ始めた頃には、最終的に表示された組み合わせのデータすらありませんでした。数か月間後(Google Ads API v12, 2022-10)には、各組み合わせと表示件数(impressions, またはimp数)がAPIから取得できるようになりましたが、依然としてclick数は取得できませんでした。
Click数のデータは現在も、広告オブジェクト(広告運用者が管理ができる、広告プラットフォーム上に存在するもの)では取得できますが、広告インスタンス(エンドユーザーに表示される都度)のレベルの情報は取得できません。
※余談:組み合わせのimp数データを使って、同じ広告オブジェクト下の各組み合わせにclick数を割り当てることはできそうですが、imps数とclick数に予測可能な相関関係があるのかはまだ検証できていません。
RSAの分析の難しさは都度都度の可変性に留まりません。その短期的な可変性に加えて中長期の可変性もあります。なぜかというと、RSA広告オブジェクトは基本的に長く運用するものです。つまり、ETA時代のように新規の広告をどんどん作るより、同じRSA広告オブジェクト内のアセットを徐々に差し替えて行くのが基本的な運用です。
その運用の仕方には様々なメリットがあります。まずは、新規作成より手間とタイムラグが少ないことがメリットです。新規のRSAを作るのには少なくとも3つの見出しと2つの説明文を登録する必要があります。しかし、多様なパターンを網羅するためには、その最小限より多くのアセットを登録することが推奨されています。しかも、アセットごとに審査に通る必要があるため、運が悪ければ表示されるまでに余計なタイムラグが発生してしまいます。差し替えだけをする場合、審査が通っているものはそのまま使われますので配信が途切れません。
もう一つのメリットは最適化の持ち越しです。プラットフォーム側で様々な検証と最適化が自動的に行われています。新規RSAオブジェクトを作る場合、既存のものとほぼ同じアセットを使ったとしても、最適化などは全部ゼロからやり直されます。しかし差し替えだけであれば、差し替えられた分の「学習」が進んでいるあいだ、既存の最適化は適用されるため広告のパフォーマンスへの影響は緩和できます。
しかし、システム上の手間とタイムラグは省けたとしても、差し替えたアセットの効果次第で、その差し替え自体が無駄だったことになりえます。また、全体的なパフォーマンスを下げてしまう可能性もあります。実運用に移す前に色々なアイディアとアセットの効果をシミュレートできれば、既存のものより良いアセットを見つけられますし悪手も避けられて一石二鳥です。
そんなメリットの多いRSAのパフォーマンスの予測は、どうやって作れるでしょうか。テセウスの船 を彷彿とさせる、このコロコロ変わるものはどう扱えば、動作が予測可能になるのでしょうか?
オッカムの剃刀をぶん回した
情報を整理しましょう。
- RSAの広告インスタンスの内容は、非公開のアルゴリズムで組み合わせられています。
- RSAのclick数とimp数は、広告オブジェクト単位では取得できますが、広告インスタンス(実際のテキスト組み合わせ)単位では取得できません。
- 広告オブジェクトは長く運用されるもので、内容は変わる可能性があります。
- 表示位置の固定機能はありますが、利用を最小限におさえることが推奨されています。
上記の問題点に対して、こう考えました。
- 組み合わせの細かいルールなどを探るのは断念する
- その部分はGoogle社のみ知るところですので、いつ、どうやってチューニングや変更が入ったかは私たちからは見えないため、注力するところではありません。
- アセットごとではなく、アセットの集合単位で考えていく
- 実際に組み合わせられたアセットが見られないなら、アセット単体での効果が計算できません。
- 広告クリエイティブ制作においてアセット単体の効果が知りたいのは分りますが、RSAでは1アセットはその周りにあるアセットとの相互効果があるため、アセットごとのパフォーマンスを算出するのはこの問題において本質的ではないとも言えます。
- アセットが変わっていない期間ごとに区切ってみる
- アセット差し替えの頻度・差し替えタイミングや承認の待ち時間、最適化の学習時間はまちまちですし、検索ボリュームも日によって違いますので、ある程度それらを吸収できる粒度にするために、月単位にしてみましょう。
- 登録されているが承認待ちか却下されたせいで配信に使われない「無効」のアセットを除外するべきです。
- 表示位置の固定の設定の変更は厳密に言うとテキストが変わりませんが、理論上アセットの選出と下流への影響があるはずなのでアセット変更の条件の一つにしましょう。
- 固定位置ごとに何個のアセットが固定されたかだけを特徴量にしてみる
- 利用自体あまり推奨されていないので、このあたりのデータは少なそうです。とはいえ、その有無は組み合わせと最終的なパフォーマンスに影響しそうです。
- どのアセットがどの位置に固定されたのか、学習データでのアセットの順番とかで変なことが学習されてしまいそうです(例えば、「xyz」のテキストが固定されていることを学習するより、登録されているアセットの2個目が固定されていることを学習してしまうかもしれません)…
正直なところ、ここまで色々な要素を抽象化しても予測ができるか、ずっと不安を抱えていました。
生のCTRには扱いづらさがある
皆さんはなんとなくお分かりかと思いますが、検索広告の効果にはムラがあります。たくさんクリックされる広告は滅多になく、多くはほとんどクリックされません。訴求している商品やサービスの需要が低ければ、そもそも表示されません。上記のように、区切っている期間の長さがバラバラであれば、そのムラを強調させてしまう場合もあります。そして数学的に変なことが起きてしまいます。
CTRは、click数をimp数で割るという、とてもシンプルな式で計算しています。しかし、imp数の大きさによって、1 clickの見かけの「価値」が違います。
1 click / 10 imp = CTR 0.1 (10%) 5 click / 10 imp = CTR 0.5 (50%) 1 click / 100 imp = CTR 0.01 (1%) 5 click / 100 imp = CTR 0.05 (5%)
上記の例から見ると、CTR 0.5のケースは最強に見えますが、そもそものimp数は10しかありません。表示すらはほとんどされていないので、決して良い広告とは言えません。クリックされる割合は悪くない指標ですが、そのクリックの実数のほうが大事です。何かの正規化をかければ、想像している「価値の感覚」に寄せられます。
そこで、VACTR (Value-Adjusted CTR, 価値調整CTR)を提案し、使ってみました。
VACTR (imps, clicks) = (clicks / imps) / (1 + 1.1^(-imps + 50))
式だけ見ても、やりたいことはわかりづらいので、下の図を見てください。

(100 / (1 + 1.1-x + 50) ※被除数は普段0.0~1.0の連続値ですが、効果を見やすくするために100にしました。
この図のx軸はimp数で、y軸はCTR 100%の場合の、価値調整後の値です。解釈として、imp数が50を下回るほど、CTRの「価値」は小さくなります。imp数が10以下になると、生CTRが100%だとしても、調整後のVACTRは2%ほどになります。逆に、imp数が50を超えたら、その価値へのペナルティが緩和されます。imp数100以上になると、生のCTRと同じ値になります。
もちろん、式に使っているパラメーターが恣意的な箇所があることは認めます。もし、「月間imp数1000じゃないと意味がない」という運用をしたいなら、「50」のところを「1000」に替えてもいいと思っています。ただ、それをやると多くのケースが0.0同然になり、区別が付けなくなります。こればかりは、使っているデータの性質に基づいて調整するべきだと思います。今回は少なくてもimp数が100以下の場合の1クリックごとの「過剰評価」を何とかしたかったのです。
この正規化は、のちほど説明するMLPHCF実験パラダイムの初期ごろに思いつきました。いくつかの実験において、生のCTRからVACTRに切り替えて学習してみたら、相関係数が0.1~0.2ほど上がり、ロス値も著しく下がりました。そして、それ以降、他の実験パラダイムの実験を含めて、VACTRを目標値にしていました。
前回のハンドクラフト特徴量の再登場
RSAの見出し(Title)と説明文(Description)のセットが同じである期間(Period)ごとのレコード(TDSet-Period)に区切ることはできました。その中から、RSAの最低条件(有効な見出し3つ、有効な説明文2つ)を満たさなかったレコードもありましたので、削除しました。これで、テキストデータを中心にしたRSAのパフォーマンス予測に挑めます。
前回のETA効果予測と同様、使った正規表現をベースにしたタグ付与装置を使って特徴量を抽出しました。

ただ、エンコーディングは前回と違うやり方をしました。
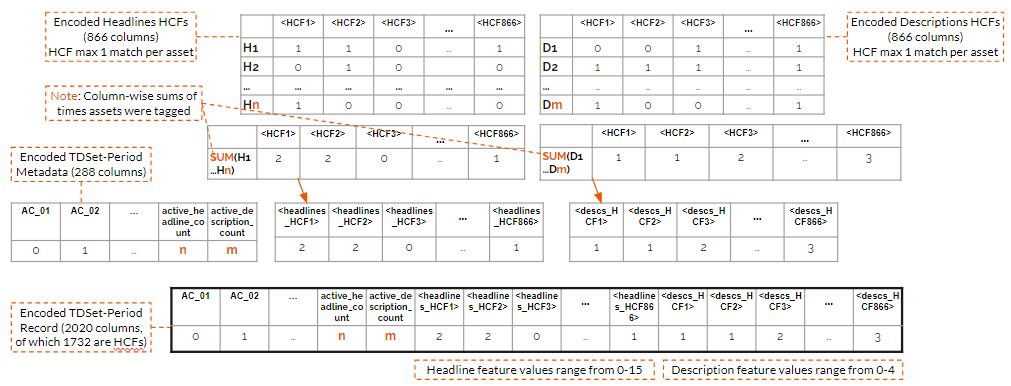
注:「headline」は「title」と同じく「見出し」のことを指しています。
前回は特徴量の有無だけを見ていたので0か1かにエンコードしていましたが、今回は登録されているアセットの数が可変であることを考慮し、1アセットの最大1回のマッチ、アセットの種類別に特徴の出現回数を合算しました。そして、有効なアセットの数も特徴量に入れました。
使ったメタデータとエンコーディング後の特徴量の数と数値の範囲は以下の通りです。
- デバイス: 4 {0, 1}
- ネットワーク構成: 2 {0, 1}
- 業界(業種の上位セット): 27 {0, 1}
- 表示位置べつの固定されたアセットの数: 5 {0, 1}
- 有効な見出しの数: 1 {3~15}
- 有効な説明文の数: 1 {2~4}
さあ、実験だ!
ハンドクラフト特徴量を用いたモデルが本命だとは言っても、他の手法も試さないと本当に良くできているかどうかが分りません。
このセクションに記載されている実験は全部1枚のGPUがついているGoogle Colab Proで行いました。ランダムシードは固定されていて、全実験において共通でした。学習率のスケジュラーも使っていました。ハイパーパラメータチューニングは実験管理ツールであるWandBのSweeps機能で行いました。
実験パラダイムによって、数回から数十回の実験(各種パラメーターの組み合わせで実行したもの)をしていましたが、以降のサブセクションにはベスト候補の構成やパラメーターが記述されています。最低のvalidation lossを達成できた実験をベスト候補に選びました。
MLPHCF: Multilayer Perceptron with Handcrafted Features
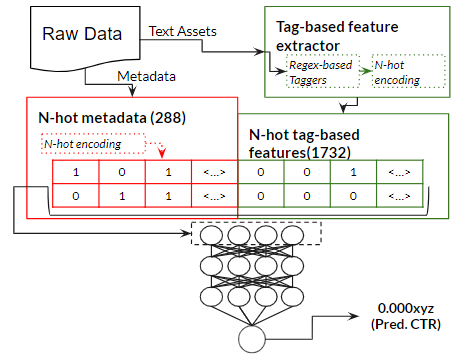
今回のベストハイパーパラメーターは:
- 400ノードずつの11層
- 入力の直前にDropout(rate=0.1)
- バッチサイズ128, 初期学習率 0.00005
- 出力ノードはReLU
FTLLM: Fine-tuned Large Language Model
HuggingFaceのMobileBertForSequenceClassificationで、ysakuramotoさんの事前学習済みMobileBERTをファインチューニングしました。
○○ForSequenceClassificationは本来、回帰ではなく分類用のクラスですが、オブジェクトを作るときに(num_labels = 1)と設定すれば出力は1個の連続値になります。
他にDistilBERT と ALBERT をファインチューニングしてみましたが、入力の綴り方によって学習が進まなかったケースもありました。今回試した中で、MobileBERTが一番安定に学習していたため、この実験パラダイムの代表的な候補にして、下流の実験にも使いました。
データの入力の仕方は、下記の通りに行いました。
- メタデータを言語化にして、1ホワイトスペースを挟んでjoin()しました。
- 1レコード(TDSet-Period)の見出しのテキストを1ホワイトスペースを挟みながらjoin()しました。表示位置が固定されている場合、そのテキストの直前に「固定見出し<1~3>」という文字列をくっつけました。
- 1レコードの説明文のテキストを1ホワイトスペースを挟みながらjoin()しました。表示位置が固定されている場合、そのテキストの直前に「固定説明文<1~2>」という文字列をくっつけました。
- 1.~3. の結果を[SEP]トークンを挟んでjoin()しました。
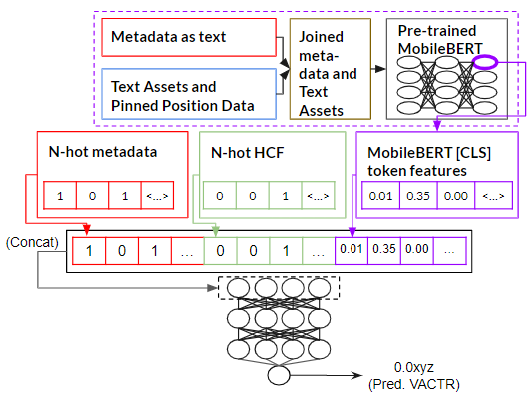
MM: Multimodal Learning
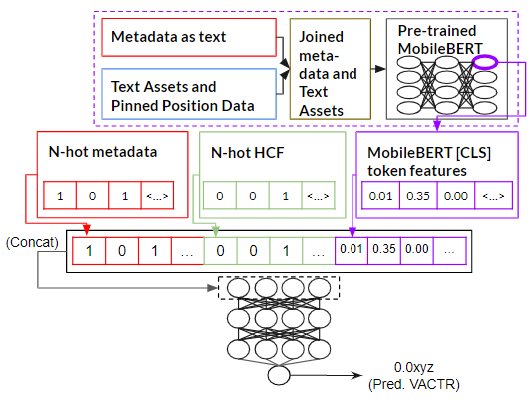
簡単にいうと、ネットワークはMLPHCFと同じですが、MobileBERTで入力特徴量を増やそうとしてみました。
- ファインチューニングしてない学習済みMobileBERTオブジェクトに、先述した連結された言語化メタデータとアセットテキストを入力しました。
- 最後のレイヤーの1ノード目([CLS]トークンに該当する)から埋め込みの配列を取得しました。
- Encoded TDSet-Periodにその埋め込み配列をくっつけました。
- 3.の結果でMLPを学習させてみました。
そのMLPの構成は:
- 800ノードずつの5層
- 入力の直前にDropout(rate=0.1)
- バッチサイズ16、初期学習率 0.00001
- 出力ノードはReLU
性質上、埋め込み配列の中の数値はEncoded TDSet-Periodの数値の規模が違うので、正規化なども試しましたが、正規化なしのパターンが一番良かったです。
JL: Joint Learning
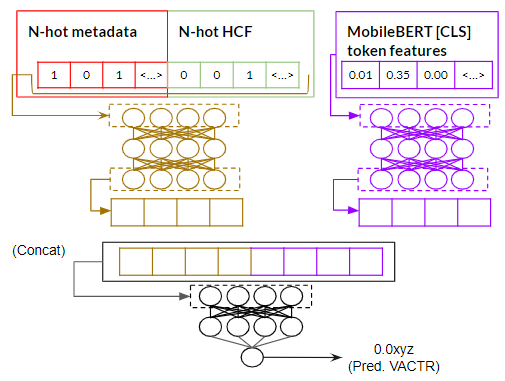
2種類の特徴量を分けて、その特徴量ならの学習が進める独立した「空間」を与えて、同時に同じタスクを学習する構成です。
この実験パラダイムにおけるベストハイパーパラメーターは:
- 2 サブネットワーク(MLP)
- 600ノードずつの5層
- 入力の直前にDropout(rate=0.1)
- ジョイントリグレッサー(MLP)
- 600ノードずつの2層
- 入力の直前にDropout(rate=0.1)
- 出力ノードはReLU
- バッチサイズ16、初期学習率 0.00001
Ens: Ensemble
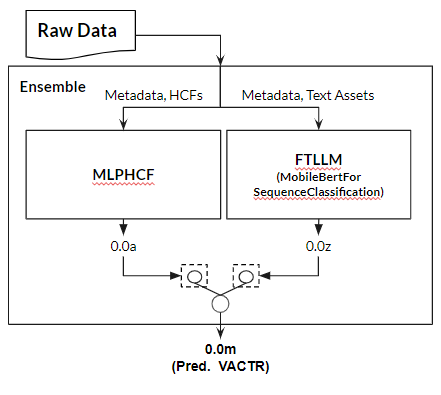
最後に、MLPHCFとFTLLMの最強モデルでアンサンブルモデルを作ってみました。そのアンサンブル装置は:
- 入力2個と出力1個のLinear 1層
- バッチサイズ16、初期学習率 0.001
その結果は?
その前に、一つの注意点です。 ほとんどの実験においてどこかのタイミングで、training lossが減少していてもvalidation loss が逆に増えてしまいます。これは過学習の可能性をしめす信号です。なので、実験の最後のエポックではなく、validation lossが最低だったエポックの時点の学習物を使って下流の検証を行いました。
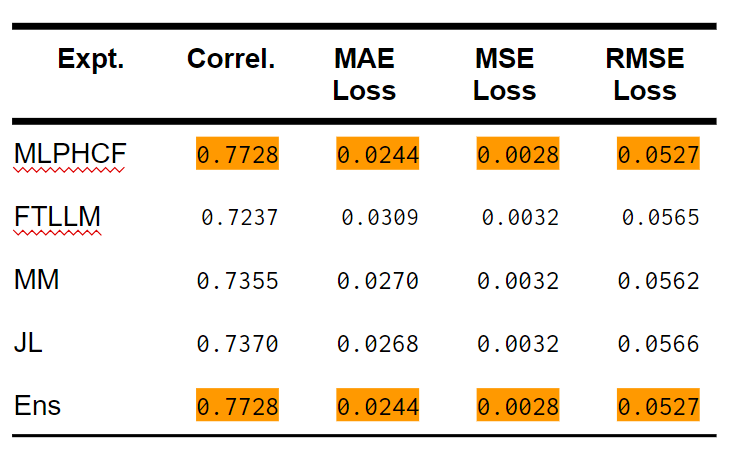
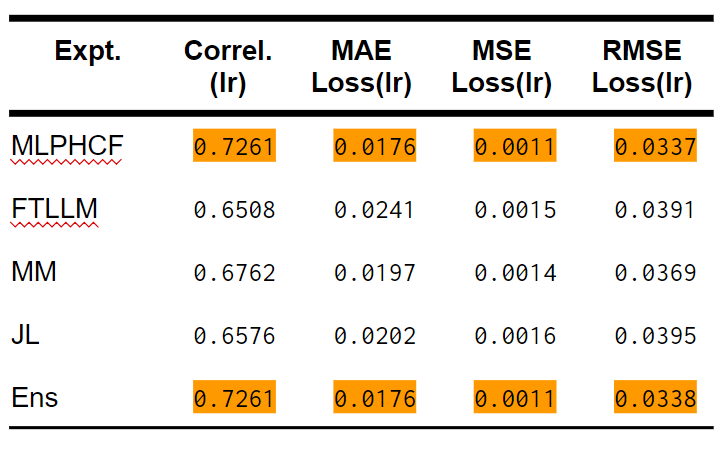
Correl.は相関係数、MAE Lossは平均絶対誤差に基づいたloss値、MSE Lossは平均二乗誤差に基づいたloss値、RMSE Lossは二乗平均平方根誤差に基づいたloss値です。 ※ 論文にかかれたJLのMSE LossとRMSE Lossの数値は間違っていました。この表に書かれている値が正しいです。
表から見て、MLPHCFとEnsは同じに見えます。小数点第4位以下でも数値が同じなので、念のためにEnsの実装は間違っていないかを確認しました。Ensの予測値からMLPHCFの予測値を引いて、平均をとったら0.00028の平均差異がありました。Ensの予測値からFTLLMの予測値を引いて平均をったら、平均差異は-0.00634でした。結局、Ensモデルが学習した、MLPHCF対FTLLMのウエイトは[0.8064, 0.2010](合計1.0に正規化して、[0.8005, 0.1995])で、かなりMLPHCFに寄せていることがわかりました。
今回の5つの実験パラダイムのなかから、MLPHCFの精度が最高だったことは明らかだと思います。
テキスト広告界隈ではCTRの常識的な限界は20%とされています。テストデータセットから、実際(ground truth)のVACTRが0.2未満のケースに絞って検証しました。絞った後のケース数は、テストデータセットの 94.035%を占めました。念のために全データを同様に絞ってみましたが、全データ数の94.7138%が含まれました。生のCTRではなくVACTRでしたが、「ほとんどのテキスト広告のCTRは20%以下」と言われているだけありますね。
この数域においてMLPHCFの有利も明らかだと思います。
わざわざ特徴量をつくる?ファインチューニングで良くない?
でも、ハンドクラフト特徴量を作る必要はありますか? 目標によるかなと思います。
ハンドクラフト特徴量のセットを作るのは大変です。対象にしている分野のドメイン知識が必要ですし、表現性(網羅できる現象の数)とセットのサイズの駆け引きも考える必要があります。その上に、その特徴量をうまく学習するネットワークも構築しないといけません。
今の世の中は、off-the-shelfの事前学習済みモデルが富んでいます。何とか使えそうなモデルをクイックに作るのには、うってつけです。実際、そうやったらもっと楽できたかもしれないと思う時もあります。
しかし、私の目的は「精度」だけではありませんでした。解釈可能性、長期運用のコスト、使用する資源の減少、どれも捨てない「価値観のよくばり」な性格でもあります。それを貫いた結果で、「一つのプロダクト」を作るのに1年間もかかってしまいましたが、予測の精度だけではなく、そのボーナス目標を全部達成できたかなと思います。
その結果を見て話していきましょう。
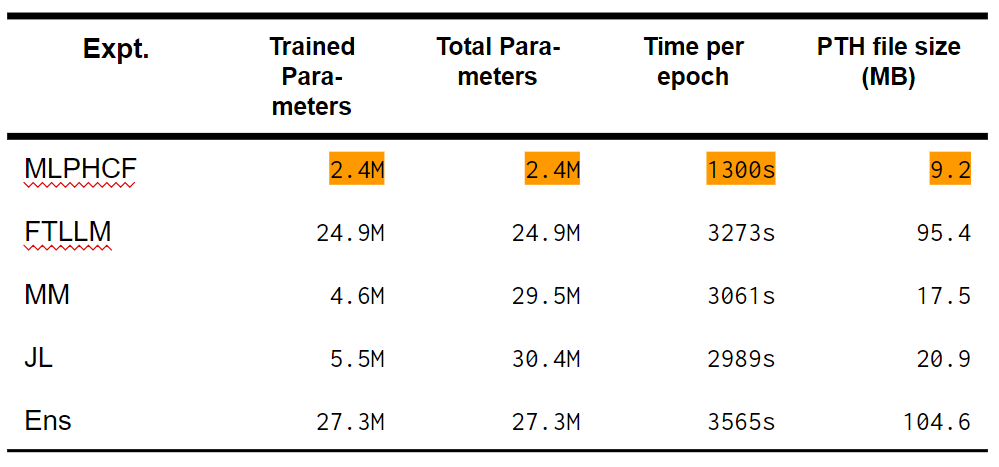
まず、各実験パラダイムのパラメーターの数に着目しましょう。「Trained Parameters」は学習過程で調整されるパラメーターを指しています。「Total Parameters」は学習過程で調整されないパラメーター(学習済みLLMの内部)とTrained Parametersの合計です。「Time per epoch」は、特徴量生成を含めた全部の処理が行われる1エポック目の所要時間です。
MLPHCFは見ての通り、軽量です。MMやJLのファイルサイズも小さく見えますが、実行する際には学習済みLLMを別途にダウンロードする必要があります。モデルのファイルが小さいからメモリーのスペックが低いマシーンでも実行できるし、インスタンスをコールドスタートからたてるためのI/Oや通信もおさえられるので全体的に早くなります。
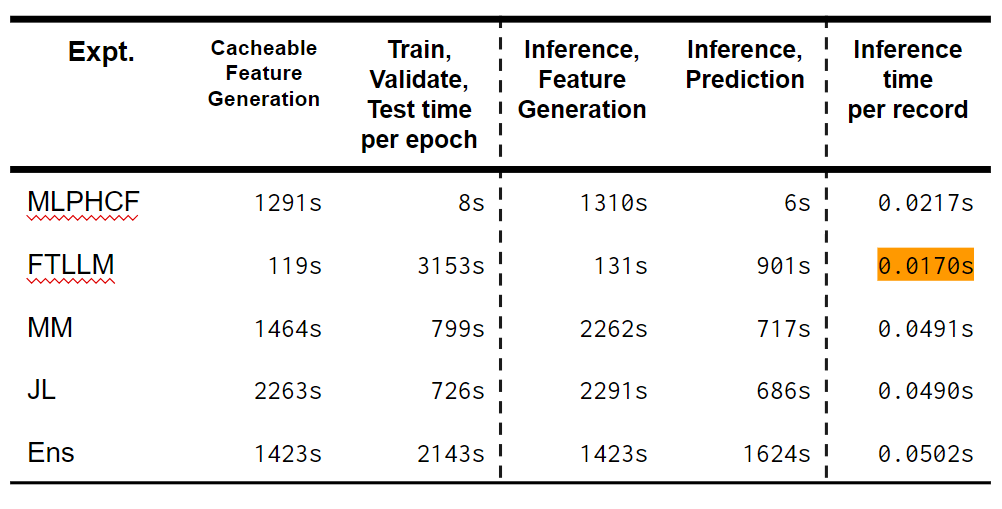
上記の表は、最後のカラムを除いて、全レコード(6万件ほど)を処理した時の所要時間を表しています。Colab Proを使っていたため、CPUのスペックは2.0GHz~2.3GHzの間のものが割り当てられていましたが、GPUは全部Tesla T4でした。
所要時間を大きく「特徴量生成」ステップと「学習ステップ」に分けてみました。時間短縮のため、1エポック目で次のエポックにも使えるベクターを作成しデイスクに保存しました。2エポック目以降はディスクからベクターを読み込めば、一部の処理は省けました。その1エポック目で行った処理は「Cacheable Feature Generation」と呼んでいます。「Inference」のところは、学習ではなく推論だけをした場合の結果です。
MLPHCFの場合、タグ付与のステップは結構遅いですが、全部のエンコーディングを経てそのままニューラルネットワークに入力でき、かつcacheableなベクターができます。一回作ったらディスクから読み込めばいいので、2エポック目から入力ベクターを用意するのに1秒もかかりません。
しかし、FTLLMの場合、cacheableな部分はtokenizerから出力されるinput IDのデータです。FTLLMまたLLMを使った手法では省ける処理はほとんどありません。
とはいえ推論だけをした場合、FTLLMのほうが若干早かったです。MLPHCFに使われるタグ付与装置は現在1スレッドでCPU上に動いているものです。並行処理を実装すれば、FTLLMより早くなる可能性は高いと思います。
しかも、MLPHCFのネットワークのパラメーター数は割と少ないので、数件程度の予測をするのにGPUなしの環境でもほぼリアルタイムに結果が出ます。実は、社内のユーザーが使うと想定していたツールの予測部分は、GPUがついてないCloud Functionにデプロイしています。それでも1~3件のRSAの予測は5秒以内に戻ってきます。コールドスタートがない場合、1秒もかからない程度です。GPUのない環境でFTLLMを使おうとした場合、1件の予測には数十秒もかかるでしょう。
逆に、ハンドクラフト特徴量にはどんな利点があるの?
断っておきます、このセクションに話す内容は自分の解釈と意見に基づいたものです。サイエンス的な根拠は十分に示せてないし、関連する論文なども十分には読んでいません(自分が悪いのは自覚しています)。ただ、それでもハンドクラフト特徴量の可能性が気になるのであれば、読んでもらえれば幸いです。
ハンドクラフト特徴量の反対ともいえる「learned features(完全自動で見つけられた特徴量)」は、与えられたデータの中の共通点を見つけることは得意です。構造化すれば、より大きい特徴も見つけることができるでしょう。コンピュータービジョンの例をするなら、「線特徴量」 -> 「閉じた図形特徴量」「多角形特徴量」 -> 「空いた目っぽい特徴量」「閉じた目っぽい特徴量」「閉じた口っぽい特徴量」「空いた口っぽい特徴量」 -> 「顔っぽい特徴量」、のような特徴量の構造が自然に学習される可能性はあります。データが十分であれば、人間には思いつかない現象を見つけて、最終的なパフォーマンスは人を超えるのもあり得ます。
ハンドクラフト特徴量は、専門家などのドメイン知識をベースに作られていますので、自然にあった現象だけではなく、その現象や現象の集合体の「価値」や「意味」を明示して学習させることができます。
さっきのコンピュータービジョンの例にたとえるなら、「顔っぽい特徴量」には「空いた目っぽい特徴量」と「閉じた目っぽい特徴量」を含有していますが、「目の特徴量」がないので、半開き目の顔を見落とす可能性はあります。アニメなどには3個以上の目を持つキャラクターは登場したりしますが、それを見た人間は「変な顔」と思いながらちゃんと顔があることを認識しています。しかし、データセットにそういう顔が含まれていなかったら、「顔っぽい」learned featureには「目は2個まで」という暗示的なルールも学習されます。
もちろん、データセットを補充すればそれなりに汎用性のある特徴量構造を自然に学習する可能性はあります。しかし、一見関係なさそうな小さな現象を明示的にむすびつける「高次特徴量」は、ハンドクラフト特徴量で設計できます。同等の「高次特徴量」を自動的に学習するほどのデータ量がなくても、ハンドクラフト特徴量をうまく実装すればその現象は認識されます。
ロマン的な言い方ですが、ハンドクラフト特徴量は人の知恵を機械学習に注入する手法です。
ここら辺をもっと語りたいですが、これはエッセイではなく解説記事なので、この話はここまでにしておきます。
「成功」は多面的なものである
メトリクスだけから見ると、MLPHCFのほぼ完全勝利に見えますが、その道のりは長かったです。ハンドクラフト特徴量のスキーマの設計は時間がかかるし、一つ一つの手動チューニング(例外を除外する作業とか)はさらに時間と労力がかかります。すぐにプロダクトを作りたいなら、既存の事前学習済みモデルをファインチューニングしたほうがminimum viable productができるまでの時間は最短にできるでしょう。広告の予測は、扱っているジャンルは広いとはいえ言語的な現象は割と狭くなっています。対象にしている分野が広いほど、ハンドクラフト特徴量が十分に作れない可能性は高くなるので、FTLLM手法を選ぶのは無難ですし絶対楽だと思います。「いい感じの精度」と「プロダクト化までの時間」と「保守運用のしやすさ」が主な判断軸であれば、やはりFTLLM手法一択でしょう。
しかし「解釈可能性」や「計算資源による運用コストの安さ」や「抽象的な要素の表現性」を諦めたくなければ、ハンドクラフト特徴量を用いた手法も検討してください。
Opt Technologiesに興味のある方は、こちらから「カジュアル面談希望」と添えてご応募ください!
