
社内共有のマスタデータ基盤としてのGraphQL APIをプログラミング言語Clojureで開発している事例をご紹介します。
あいさつ
Clojurian 1のlagénorhynque (a.k.a. カマイルカ 🐬)です。
オプトでは社内向けサービス開発チームのテックリードとして、アーキテクト兼マネージャーのような仕事をしています(もちろんClojureコードを書きます)。
今から約3年前の2017年秋には、社内で初めてプログラミング言語Clojureをプロダクト開発に一部導入した事例をご紹介しました。
また、2019年夏のShibuya.lisp lispmeetup #78 2では、その後のClojure利用拡大の歴史について「征服」(conquest)と誇張してジョーク成分高めに紹介する Clojurian Conquest 3 という発表もしたことがありました。
現在のオプト(その開発組織Opt Technologies)でのClojure利用については「日本で Clojure/ClojureScript を利用している会社一覧」でも公開していますが、
社内依頼管理システムのバッチ、広告入稿支援ツールのREST API、広告媒体アカウント管理システムのGraphQL APIと3つあります。
今回の記事では3つ目のGraphQL API開発についてご紹介しましょう。
新規API開発の背景
現行システムの問題点: 共有データベース
Opt Technologiesが開発しているプロダクト一覧でも紹介されている広告媒体アカウント管理システム「アムズ」4。
広告媒体のアカウントをはじめとした広告運用業務のための各種マスタデータをこのシステムのデータベースが保持し、これまで社内の様々なサービスで共有してきました。
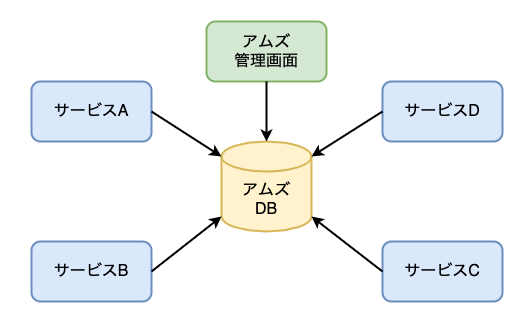
典型的な「共有データベース」という設計パターンです。
この共有のデータベースが健全にメンテナンスされていれば大きな問題にならずに済む可能性がありましたが、現実には一貫した設計思想も健全性を保つ仕組みもなく増改築を繰り返す過程で多くのリスクを抱えるに至ったようでした。
- テーブル群が命名の一貫性も外部キー制約もなく乱雑に存在し、典型的なRDB設計のアンチパターン/バッドノウハウの宝庫になっている😇
- 暗黙の仕様がアプリケーション(「アムズ」の管理画面)に漏れ出しているため、「アムズ」全体を正しく理解してないとデータの扱い方を容易に間違えてしまう😇
- 多数のサービス間で直接的に自由に共有されているため、データベーススキーマの変更が利用側サービスに直ちに波及してしまう😇
解決策: データベースをラップするサービス
オプトの広告運用業務を支える基盤となるマスタデータがこのように扱われていては、今後ますます複雑に高速に進化していくプロダクト群を支えていくことができず、極めて深刻な技術的負債になってしまう可能性が高い。
そこで「アムズ」のAPI化構想が生まれました。
「アムズ」のデータベースをサービス(API)として疎結合に抽象化することで
- マスタデータを利用しやすくする(利用側サービスの開発者が実装の詳細や歴史的経緯を知らずに済む)
- マスタデータを保護しつつAPIとして素早く機能追加できるようにする(アクセスパターンに一定の制限を設けながら非破壊的な機能変更を素早く積み重ねる)
- マスタデータのデータベースリファクタリングを実現可能にする(他サービスからの直接的依存をなくすことでデータベースをサービス(API)の実装の詳細にする)
というアイディアです。
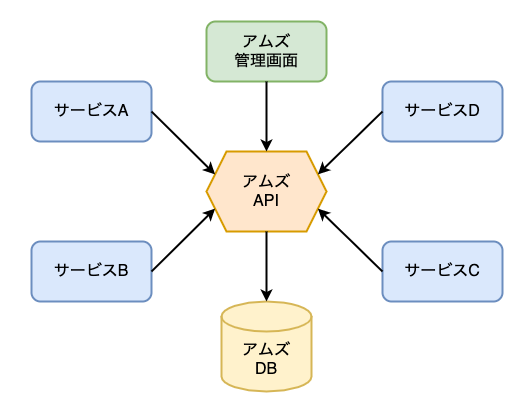
2018年冬に開催された「開発合宿2018」では、この企画について具体的な検討を進めるとともにClojureとGraphQLによるプロトタイプ開発に取り組みました。
そして2019年10月、正式に「アムズAPI」という新プロダクトの開発チームが発足しました。
技術選定の経緯
レガシーデータベースを抽象化するAPIを開発するという方向性が明らかになったあと、実際にプロダクトとしての開発が始まるまでには、主要な技術の選択肢についての議論がありました。
API方式: GraphQL
社内でバックエンドにAPIを開発するというとこれまでREST APIとして設計するのが一般的でしたが、2018年冬の時点でGraphQLに興味を抱いていた私は、今回の用途にGraphQLはとてもよく合うかもしれないという予感がありました。
バックエンドのサービス間通信の方式としてはgRPCももちろん選択肢として考えましたが、個々のクライアントが興味のあるデータを必要な範囲まで過不足なくまとめて取得できる可能性を秘めたGraphQLというAPIインターフェースが非常に魅力的に感じられたためです。
「アムズ」というマスタデータ管理システムのデータベースは保持しているデータが特別に複雑というわけではありません。
しかし、社内のマスタデータ基盤としてこれから幅広いユースケースに応える必要がある状況で、APIの破壊的変更を避けてインターフェースの安定性を確保しながらそうしたユースケースに素早く対応していくには、グラフ構造のデータモデルで様々なアクセスパターンでデータ取得できるように継続的に進化させられることは大きなメリットがありそうだと考えました。
クライアント側の自由度を高められる期待がある一方で、サーバ側でパフォーマンスを確保しつつ内部実装の複雑化を抑制するには工夫が必要なことも分かっていました。
その点にも留意しつつ上述の開発合宿では簡単な技術検証を行い、今回の目的に照らして現実的に妥当な選択肢であるという感触が得られたため、GraphQL APIとして開発することに決めました。
社内で初のGraphQL利用ということで、私自身はLearning GraphQL 5、How to GraphQLといったリソースで基礎知識をインプットし、開発チームとしてはチーム内勉強会でGraphQL公式サイト 6のドキュメントを一通り読むということにも取り組みました。
また、GitHub GraphQL APIやAWS AppSyncもAPIスキーマ設計の例として適宜参考にしました。
メイン開発言語: Clojure
GraphQL APIとして実現することを決めたところで大いに議論が盛り上がったのはメイン開発言語の選択でした。
プロトタイプ開発時には私が慣れているということもありClojureとそのGraphQL実装Laciniaを採用しましたが、これをそのまま正式なプロダクト開発でも利用するかどうかが問われたのです。
有力な対立候補としてScalaとそのGraphQL実装SangriaやCalibanがありました。
Opt Technologiesでは組織発足(2016年)当初からいくつかの主要なプロダクトはサーバサイドがScalaで開発され、Scala経験者が多数を占めてきたという経緯もあり、開発言語としてScalaが第一候補になりやすい傾向があります7。
しかし、2017年にClojureを初めてプロダクトに導入して以来、Clojure開発の実践的な知見が着実に蓄積し、勢力も拡大していました(cf. Clojurian Conquest)。
ここで一般論としての前提を確認すると、ClojureもScalaもどちらもJVM言語であり関数型言語であるという点で共通していますが、Scalaが同時にオブジェクト指向言語でもある(OOPとFPのスタイルを効果的に組み合わせることを目指している)一方、Clojureはオブジェクト指向的な言語機能や設計思想からは敢えて距離を置いた設計になっています8。
また、Clojureは動的型付き言語であるのに対してScalaは静的型付き言語です。
ある程度以上大規模なコードベースを継続的にメンテナンスするには静的型付き言語のほうが適しているという考え方が広まりつつあるようですが、Clojureはバージョン1.9でclojure.specという一種の契約プログラミング(contract programming)的な仕組みを標準ライブラリとして導入し、漸進的型付け(gradual typing)とは異なるアプローチで典型的な課題を克服しつつあります。
こうした前提を踏まえて議論した結果、ClojureでもScalaでもバックエンド開発言語として実用上申し分ないと改めて認識するに至りました。
どちらで開発することも十分可能でした(チーム内でも意見が割れました)が、最終的に決め手のひとつとなったのは、今回のAPI開発の目的に照らして変更に強く中長期的に安定して成長させ続けられるかどうかでした。
Clojureの生みの親Rich HickeyによるA History of Clojureという論文で、ClojureとScalaのコードベースの変遷が分かりやすく対比されていました。
A History of Clojureにも出てくるClojureとScalaのコードベースの変遷が対照的で面白い。
— lagénorhynque🐬カマイルカ (@lagenorhynque) 2020年6月10日
Rich Hickeyが本文で述べているように良し悪しは一概に言えないけど、両言語コミュニティの価値観の違いの一端が表れているようでとても興味深い。https://t.co/JmsfYKriqd pic.twitter.com/C4GSx9t69u
Clojureでは、標準ライブラリはもちろんサードパーティライブラリも数年以上更新されていなくてもほとんどの場合そのまま安心して使い続けることができます(他言語の感覚でメンテナンスが止まっていると勘違いされることも多いですが😅)。
言語本体と標準ライブラリについて破壊的変更がなく後方互換性が確保されていることに加えて、多機能のフレームワークのようなものよりも単機能のライブラリの組み合わせで目的を達成することを好む考え方がコミュニティの文化として定着しているためです。
ひとつの役割だけを上手く果たすものを組み合わせるほうが、大きく複雑に絡み合った塊よりも扱いやすい。
Rich Hickeyの Simple Made Easy というプレゼンテーションで語られている"simple"という価値がClojureエコシステムには浸透しているのです。
cf. "Simple Made Easy" Made Easy
Clojureコミュニティにおける"simple"(対義語として"complex")概念は設計の良し悪しを考える指針のひとつとなるものですが、これはUNIX哲学の「一つのプログラムには一つのことをうまくやらせる」、オブジェクト指向設計の「単一責任の原則」(single responsibility principle) 9、モノリシックアーキテクチャよりもマイクロサービスアーキテクチャを志向する潮流などにも本質的に重なりがあると考えられます。
確かに、Clojureという言語はもともとニッチを押さえる戦略で登場した言語であり、まだまだ国内はもちろん世界的にも巨大なコミュニティなど存在しません。
したがって大規模なコミュニティを持つ言語とはリソース面でとても勝負できません。
しかし、小さな言語コミュニティでは使えるライブラリもツールも少なく厳しいだろうという一般的な予想に反して、JVM/Javaの堅牢な基盤と豊富な資産を最大限に活かせるだけでなく破壊的変更なく安定した"simple"な言語/ライブラリとそれを支える成熟したコミュニティが存在することにより、長く安心して使えるというのがClojureの非常に大きな強みだと考えています。
Rich Hickeyも前述の論文 A History of Clojure で
I wanted Clojure to be a stable tool for professionals, not a platform for experimentation.
と書いています。
プログラミング言語とそのコミュニティによって目指すものや重視する価値は異なり、もちろん良し悪しは一概に言えませんが、仕事でも趣味でも様々な言語を扱ってきた中でClojureの安定性(stability)とシンプルさ(simplicity)はとても魅力的だと私自身も長らく実感しています。
こうした実用上のメリットも含めてさらに議論し、Clojureで開発することにチームで合意しました10。
ちなみに、GraphQL APIのバックエンドとしてAWS AppSyncも候補として検討しましたが、扱うデータベースがAmazon RDSであり、AppSyncとは相性があまり良くないようであったことから選択肢から外れました。
GraphQLと同様にClojureについても未経験のチームメンバーが多いため、入門支援は積極的に行いました。
「Clojure/ClojureScript関連リンク集」という私がメンテナンスしているリンク集にClojure関連の主要な情報源を集約し、
開発で利用する主な要素技術に関する日本語の入門記事を書き、チーム内勉強会で入門書 Getting Clojure を読み進めたり、コードレビューやペアプログラミングを通してClojureらしいコードの読み書きのしかたを伝えたり、定型的な問題はフォーマッターやリンターで自動チェック/自動修正されるようにしたりしました。
チーム開発が始まった2019年10月時点ではチーム内で私しかClojureコードを読み書きできない状態でしたが、現在ではアプリケーション開発を担当するメンバー複数名にClojureでの機能開発はほとんどお任せして、私自身はアーキテクトとして設計方針に関する議論をリードしたりアプリケーションの共通基盤機能を整備したりコードレビュー時に設計/実装の一貫性が確保されるように助言したりするだけで開発が進む状態になってきています。
アプリケーションのアーキテクチャ設計
The Clean Architecture
今回のAPI開発では技術選定において変更に強いことを重視した選択を行いましたが、アプリケーション全体としてもThe Clean Architectureを意識した疎結合なアーキテクチャを目指しています。
開発言語がClojureであること、APIのインターフェースがGraphQLであることも踏まえて、以下のようなレイヤーで構成してみました。
- resolver (リゾルバ)
- GraphQLサーバでフィールドの値を解決する関数のための名前空間
- use case, entityにとって実装の詳細
- use case (ユースケース)
- entity (エンティティ)
- boundary (バウンダリ)
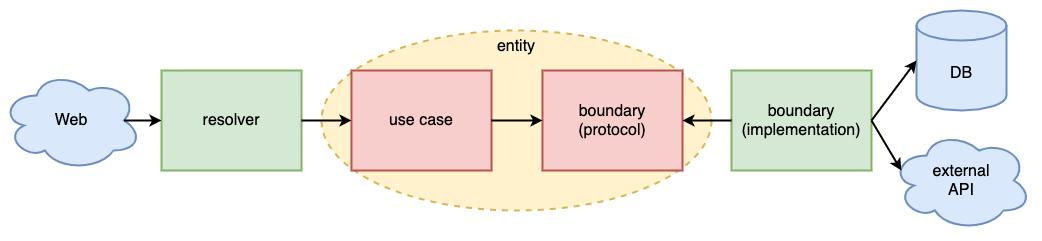
コードの全体像
ここで「アムズAPI」のGraphQLクエリ members (「メンバー」一覧取得)を例に、アーキテクチャ設計に対応した実際のプロダクトコードを簡単に示します。
Clojureプログラムを読み慣れていない方にも全体的な雰囲気が伝われば幸いです。
resolver
(ns ams-api.resolver.members "メンバーリゾルバ" (:require [ams-api.use-case.member :as member] [ams-api.util.resolver :refer [defresolver]] [ams-api.util.validator :as validator :refer [when-valid]])) (defresolver list-members [context {:keys [pagination_input] :as args} _] (when-valid [nil args [:map validator/pagination_input validator/sort_inputs [:name {:optional true} validator/schema-maybe-non-empty-string]]] (let [{:keys [members total_count]} (member/find-all context args)] {:nodes members :pagination (assoc pagination_input :total_count total_count)})))
defresolver list-members がGraphQLのフィールドの値を解決する関数の定義です。
入力バリデーションでエラーがなければ use case の関数を利用して「メンバー」のノードリストとページネーション情報を返します。
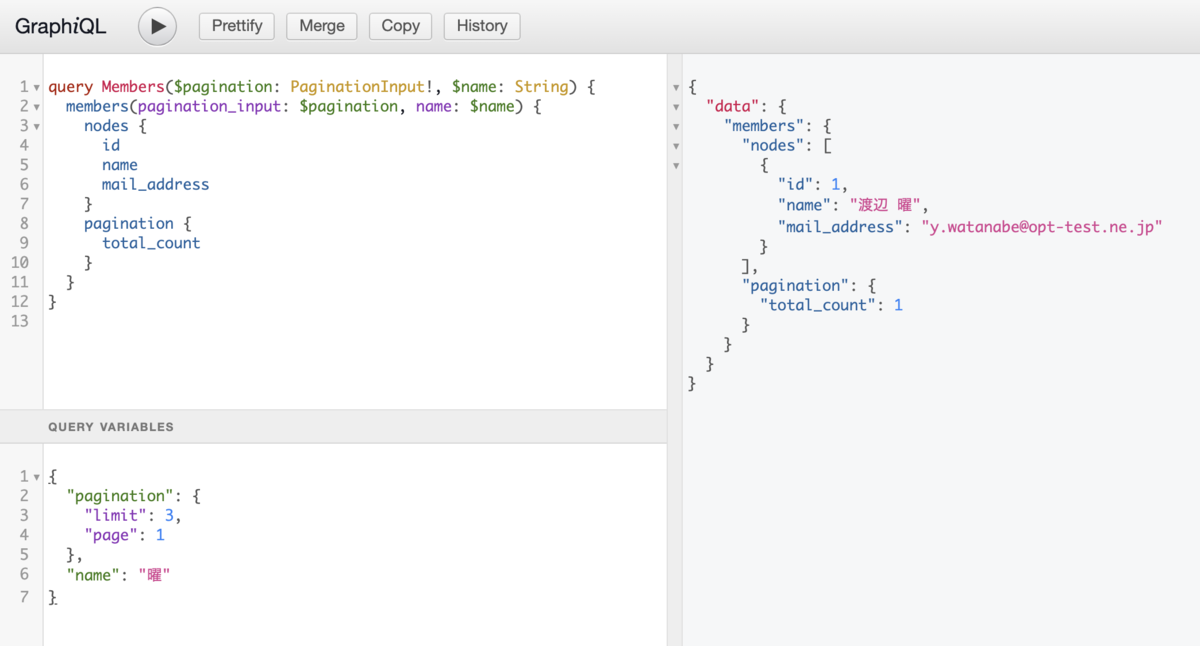
実際の動作はGraphQLのブラウザIDE "GraphiQL"から確認することができます。
use case
(ns ams-api.use-case.member "メンバーユースケース" (:require [ams-api.boundary.db.member :as db.member])) (defn find-all [{:keys [db]} condition] {:members (db.member/find-members db condition) :total_count (db.member/count-members db condition)})
defn find-all が「メンバー」の一覧情報を取得するというビジネスロジックを表現した関数の定義です。
boundary の関数を利用してDBのデータを取得します。
ClojureのREPLから例えば次のように関数の動作を確認することができます。
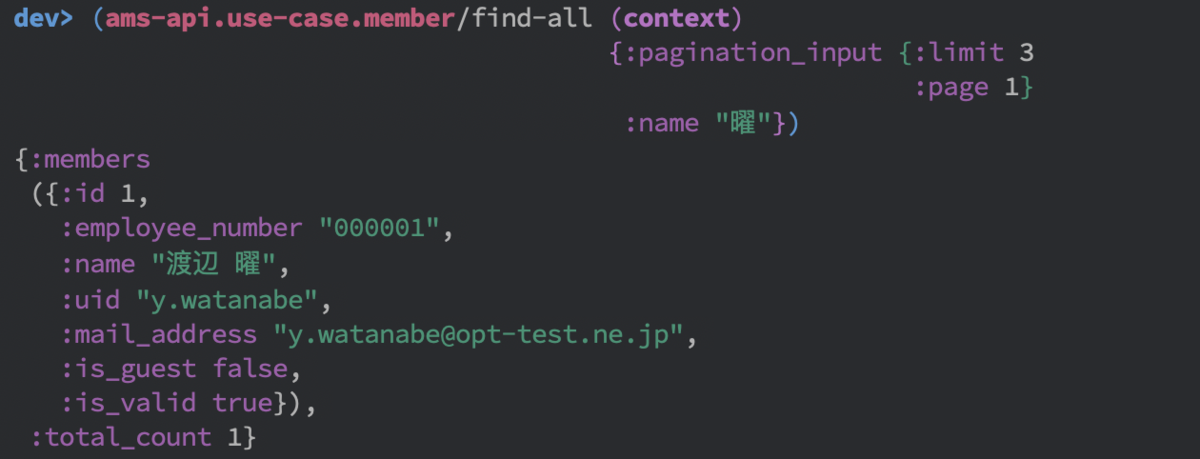
entity
(ns ams-api.entity.member "メンバーエンティティ" (:require [ams-api.entity.shared] [clojure.spec.alpha :as s])) (s/def ::id nat-int?) (s/def ::employee_number string?) (s/def ::name string?) (s/def ::uid string?) (s/def ::mail_address (s/nilable string?)) (s/def ::is_guest boolean?) (s/def ::is_valid boolean?) (s/def ::member (s/keys :req-un [::id ::employee_number ::name ::uid ::mail_address ::is_guest ::is_valid]))
「メンバー」データとはどのようなものか、clojure.specで仕様を記述しています。
開発時に boundary の関数の入出力データの検証に利用します。
boundary
(ns ams-api.boundary.db.member "DBのメンバーデータとの境界" (:require [ams-api.boundary.db.core :as db] [ams-api.entity.client :as client] [ams-api.entity.member :as entity] [ams-api.util.const :as const] [clojure.spec.alpha :as s] [duct.database.sql] [honeysql.core :as sql] [honeysql.helpers :refer [merge-order-by merge-where]])) (s/def ::name (s/nilable ::entity/name)) (s/def ::is_valid (s/nilable ::entity/is_valid)) (s/def ::company_id (s/nilable ::client/company_id)) (s/def ::select-members-conditions (s/keys :opt-un [::name ::is_valid ::company_id])) (s/fdef find-members :args (s/cat :db ::db/db :tx-data (s/nilable (s/merge (s/keys :req-un [::db/pagination_input] :opt-un [::db/sort_inputs]) ::select-members-conditions))) :ret (s/coll-of ::entity/member)) (s/fdef count-members :args (s/cat :db ::db/db :tx-data (s/nilable ::select-members-conditions)) :ret ::db/row-count) (defprotocol Member (find-members [db tx-data]) (count-members [db tx-data])) (def sql-member (sql/build :select [:m.id [:m.member_number :employee_number] :m.name :m.uid [(sql/call :case [:<> :mail ""] :mail [:<> :mail2 ""] :mail2 :else nil) :mail_address] [:m.guest_flg :is_guest] [(sql/call :case [:= :m.status const/status-valid] true :else false) :is_valid]] :from [[:ams.members :m]] :where [:<> :uid ""] :join [[:ams.company :co] [:= :co.code :m.company_code]])) (defn sql-select-members [{:keys [name is_valid company_id]}] (cond-> sql-member name (merge-where [:like :m.name (str \% name \%)]) (some? is_valid) (merge-where (if is_valid [:= :m.status const/status-valid] [:= :m.status const/status-invalid])) company_id (merge-where [:= :co.id company_id]))) (defn ->member [row] (-> row (update :is_guest const/guest_flg->is_guest) (update :is_valid const/is_valid-int->boolean))) (extend-protocol Member duct.database.sql.Boundary (find-members [db {:keys [pagination_input sort_inputs] :as tx-data}] (map ->member (db/select db (cond-> (sql-select-members tx-data) true (db/with-pagination pagination_input) sort_inputs (db/with-sort sort_inputs) (nil? sort_inputs) (merge-order-by [:m.name :asc] [:m.id :asc]))))) (count-members [db tx-data] (db/select-count db (sql-select-members tx-data))))
defprotocol Member がDBの「メンバー」データに対するアクセスを抽象化した protocol (インターフェース)の定義、 extend-protocol Member が protocol に対する implementation (インターフェースに対する実装)です。
プロトコルの関数 find-members, count-members は、第1引数に duct.database.sql.Boundary 型のデータ(DB接続情報を含んだもの)を受け取るとDBに対してSQLを実行してデータ取得を行います。
ClojureのREPLから関数を呼び出してみると、以下のように動作します。
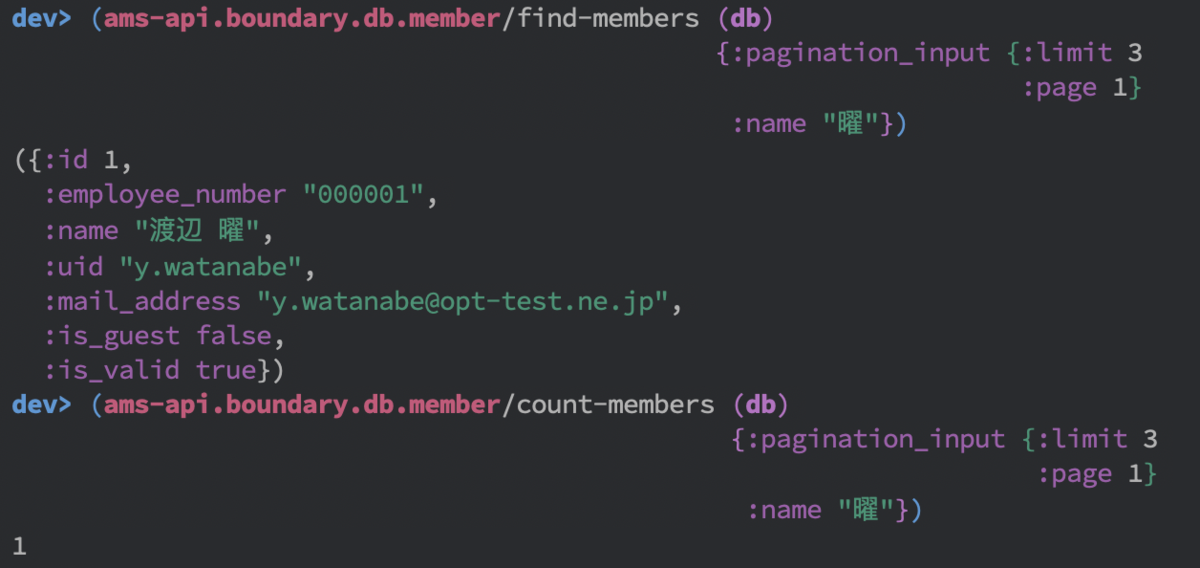
主な要素技術
最後に、API開発に利用している主な要素技術の概要をご紹介します。
アプリケーション構成の整理とライフサイクル管理: Duct
DuctはIntegrantを基礎としたマイクロフレームワークです。
IntegrantはComponentやmountと同種のライブラリで、アプリケーションの構成要素(コンポーネント)とその依存関係、ライフサイクルを管理します。
DuctではIntegrantをWebシステムのサーバサイド開発で便利なように拡張し、「モジュール」を取捨選択して利用することでアプリケーションを組み立てることができます。
GraphQL APIサーバ: Lacinia + Pedestal
LaciniaはClojureによるGraphQL実装のひとつです。
いわゆる"schema-first"なアプローチのライブラリであり、GraphQLスキーマをClojureでよく使われるシリアライゼーションフォーマットedn形式で定義することも標準のGraphQL SDL (schema definition language)で定義することもできます。
「アムズAPI」では、既存のGraphQL関連ライブラリ/ツールやクライアント側との相性、それ自体の可読性の高さを考慮してGraphQL SDLで定義しています。
APIサーバを構築するにはClojureの任意のスタックと組み合わせて利用できますが、関連ライブラリLacinia-Pedestalを利用すると、Webサービス(API)開発ライブラリPedestalをベースとしたGraphQL APIが容易に開発できます。
ちなみに、DuctとPedestalを手軽に連携させるためにduct.module.pedestalというライブラリ(Ductモジュール)を用意しました。
入力バリデーション: malli
GraphQLのスキーマ言語の型システムで記述できる制約には限界があるため、文字列長やリストの要素数などの入力バリデーションにはmalliというライブラリを利用し、リゾルバ関数の最初でチェックを実行するようにしています。
(defresolver list-members [context {:keys [pagination_input] :as args} _] (when-valid [nil args [:map validator/pagination_input validator/sort_inputs [:name {:optional true} validator/schema-maybe-non-empty-string]]] (let [{:keys [members total_count]} (member/find-all context args)] {:nodes members :pagination (assoc pagination_input :total_count total_count)})))
ここで when-valid はマクロ(macro)で、入力値 args に対して [:map ...] というデータ(Clojureのベクター)で表されたスキーマでチェックを行い、エラーがあれば本体の処理を実行する代わりにエラー情報を詰めて返します。
入力のバリデーションとエラー有無による制御、エラー情報の変換といった煩雑な処理をマクロ定義によってまとめてみました(コンパイル時に冗長な形式に変換されます)。
Lisp系言語といえば見た目に独特なS式とともにマクロで有名ですが、関数で表すのが難しい、もしくは冗長になるシンタックスを整えたい状況で非常に便利です11。
ただし、Clojure/Lispコミュニティでよく知られているように、マクロは関数よりも扱いづらく定義にも注意が必要なため濫用厳禁です。
Clojureの定番入門書Programming Clojure(日本語版『プログラミングClojure』)はマクロの用法について以下のように述べていることで有名です。
Macro Club has two rules, plus one exception. The first rule of Macro Club is Don’t Write Macros. (...) The second rule of Macro Club is Write Macros If That Is the Only Way to Encapsulate a Pattern. (...) The exception to the rule is that you can write any macro that makes life easier for your callers when compared with an equivalent function.
DBアクセス: clojure.java.jdbc + Honey SQL
ClojureではJDBCに対する低レベルなラッパーライブラリと高レベルなクエリビルダー(またはSQLテンプレート)ライブラリの組み合わせでDBアクセスを行うのが一般的です。
今回は前者としてclojure.java.jdbc、後者としてHoney SQLを利用しています。
clojure.java.jdbcはClojureの準標準ライブラリ(Clojure contrib)として安定しているため今後も安心して使い続けられるはずですが、後継ライブラリと位置付けられるnext.jdbcが登場したので移行も検討しています。
Honey SQLはClojureのデータ(マップ)によるDSLで動的にSQLを組み立てることを得意とするクエリビルダーです。
以下の例では、 sql/build でベースとなるSQLデータを用意して sql-member と名付け、 sql-select-members 関数で引数の値の有無に応じて merge-where で動的にWHERE句を追加します。
(def sql-member (sql/build :select [:m.id [:m.member_number :employee_number] :m.name :m.uid [(sql/call :case [:<> :mail ""] :mail [:<> :mail2 ""] :mail2 :else nil) :mail_address] [:m.guest_flg :is_guest] [(sql/call :case [:= :m.status const/status-valid] true :else false) :is_valid]] :from [[:ams.members :m]] :where [:<> :uid ""] :join [[:ams.company :co] [:= :co.code :m.company_code]])) (defn sql-select-members [{:keys [name is_valid company_id]}] (cond-> sql-member name (merge-where [:like :m.name (str \% name \%)]) (some? is_valid) (merge-where (if is_valid [:= :m.status const/status-valid] [:= :m.status const/status-invalid])) company_id (merge-where [:= :co.id company_id])))
ここまでに紹介したmalliのスキーマやHoney SQLのクエリをはじめとして、Clojureコミュニティではリテラルのデータをそのまま使ったデータ駆動(data-driven)なDSLが好まれる傾向があります(マクロを多用したDSLは様々な理由からあまり好まれません)。
テストとカバレッジ計測: clojure.test + cloverage
clojure.test は標準ライブラリのミニマルなテスティングフレームワークです12。
「アムズAPI」では、GraphQL APIのリクエストからレスポンスまでの実際のDBアクセスを含むE2Eテストを書き、アプリケーションアーキテクチャの各レイヤーの関数に対するユニットテストは基本的に書かない、というある意味で極端なテスト方針を採用しています。
APIサーバがクライアントに保証すべき振る舞いはあくまでもAPIが何を受け取って何を返すかであり、それ以外はサービスにとって実装の詳細にすぎないと考えられることから、API全体としての重要な振る舞いを記述するテストに注力しようと判断したためです13。
E2Eテストを多用することの懸念のひとつにテスト実行時間の長大化という問題がありますが、コードベースが着々と大きくなっている「アムズAPI」で現在のCIのAPIテスト用ジョブの実行時間はテストと静的解析などを含めて5分ほどに収まっています。
具体的なテストコードは例えばGraphQLクエリ members (「メンバー」一覧取得)に対する正常系のテストケースを一部抜粋すると、以下のようなコードになっています。
(t/deftest test-list-members (with-system [sys (helper/test-system)] (with-db-data [sys {:ams.company db-data/ams.company :ams.members db-data/ams.members}] (let [query #:venia{:operation #:operation{:type :query :name "Members"} :queries [[:members {:pagination_input :$pagination :sort_inputs :$sort :name :$name :is_valid :$is_valid :company_id :$company_id} [[:nodes [:id :employee_number :name :uid :mail_address :is_guest :is_valid]] [:pagination [:limit :page :total_count]]]]] :variables [#:variable{:name "pagination" :type :PaginationInput!} #:variable{:name "sort" :type (keyword "[MemberSortInput!]")} #:variable{:name "name" :type :String} #:variable{:name "is_valid" :type :Boolean} #:variable{:name "company_id" :type :Long}]}] (t/testing "メンバーの一覧が取得できる" (t/testing "最初のページ" (let [{:keys [status body]} (helper/run-query sys {:query query :variables {:pagination {:limit 3 :page 1}}})] (t/is (= 200 status)) (t/is (= {:data {:members {:nodes [{:id 4 :employee_number "000005" :name "北村 敦司" :uid "a.kitamura" :mail_address "a.kitamura@opt-test.ne.jp" :is_guest false :is_valid true} {:id 5 :employee_number "000006" :name "向井 市太郎" :uid "i.mukai" :mail_address "i.mukai@opt-test.ne.jp" :is_guest false :is_valid true} {:id 12 :employee_number "000012" :name "杉浦 遥香" :uid "h.sugiura" :mail_address nil :is_guest true :is_valid false}] :pagination {:limit 3 :page 1 :total_count 9}}}} (helper/<-json body))))) ;; 以下省略 )))))
ここで with-system, with-db-data はテスト用のユーティリティとして定義したマクロで、APIサーバの起動と停止、DBへのデータ投入とクリアというボイラープレートコードを背後に隠蔽しています。
また、CIではテストカバレッジ計測ツールcloverageを利用しています。
テストカバレッジはテストコードの充実度を把握する定量的な指標のひとつにすぎず、テストカバレッジを高めるために特別な努力をしているわけでもない(API仕様として必要なテストケースを整備しているだけ)のですが、本記事執筆時点で約98%と極めて高い水準になっています。
静的解析: cljstyle, clj-kondo, Joker
近年、Clojureのエコシステムでは静的解析ツールが急速に成長しており、リンターとしてclj-kondoとJoker、フォーマッターとしてcljstyleを採用しました。
clj-kondoとcljstyleはGraalVMによるnative image、JokerはGo言語製のコマンドラインツールで、これらのツールをエディタ/IDEに設定すると、JavaScriptでいえばESLintとPrettierによる自動チェックと自動フォーマットが効いている状態と同様の快適な開発体験が得られます。
ClojureといえばJavaを上回る起動時間の遅さで有名でしたが14、GraalVMでのnative image化により、従来苦手としていたスクリプティングやコマンドラインツール開発での活用も進んでいます。
Stuart Sierra (有名なClojurianのひとり; Componentの作者)による記事で2019年末時点でClojure実行環境として起動速度が非常に高速(計測結果ではC言語に数ミリ秒劣る程度)と評価されたbabashkaは、インフラ周りのスクリプティング用途で利用しています。
分散トレーシング: AWS X-Ray
GraphQL APIとしてN+1問題などパフォーマンスやアクセス負荷の問題に適切に対処する必要があり、また、「アムズAPI」は社内向けマスタデータAPIとして様々な社内サービスから呼び出される性質のものであることから、パフォーマンスチューニングや障害調査、利用実態把握などを円滑にするために、AWSの分散トレーシング(distributed tracing)サービスAWS X-Rayを導入しました。
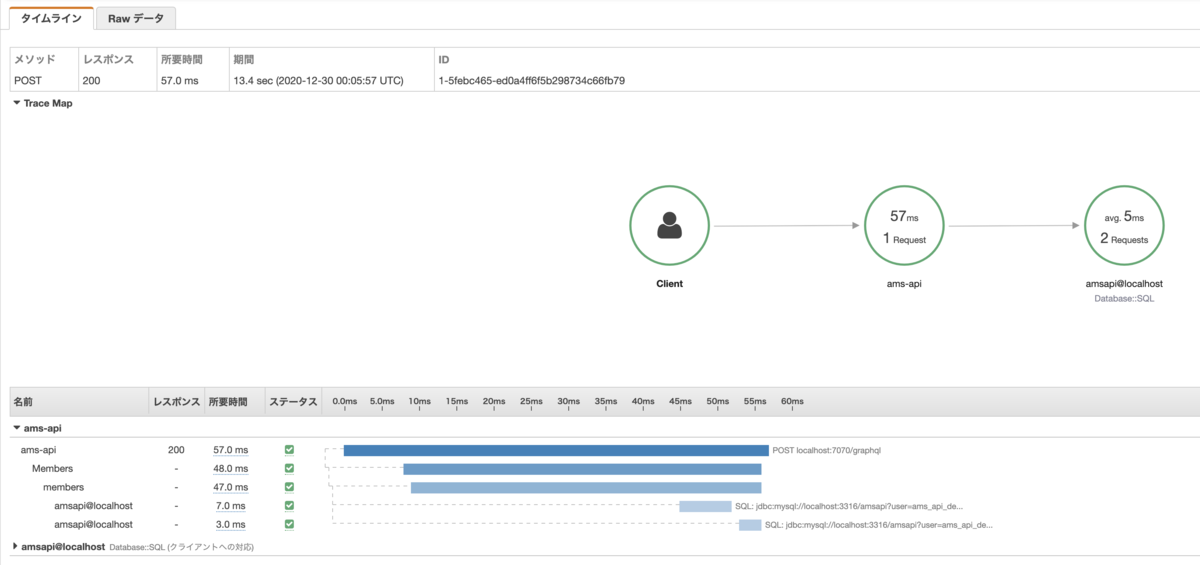
API実装言語ClojureがJVM言語で、APIサーバもPedestalがJavaのServletに対応しているため、AWS X-Ray SDK for Javaをそのまま利用してトレーシング機構を組み込むことができました。
X-Ray SDKの com.amazonaws.xray.javax.servlet.AWSXRayServletFilter でリクエスト/レスポンスごと、 com.amazonaws.xray.sql.TracingDataSource でDBアクセスごとにトレースし、また、GraphQLの実行単位であるオペレーション(query/mutation/subscription)とフィールド(に対応するリゾルバ関数)ごとにトレースするようにしています。
ドキュメンテーション/動作確認環境: GraphiQL
社内向けのGraphQL APIということで、本番環境にアクセスできるブラウザIDE GraphiQLをホストし、APIドキュメントや実際の動作の確認ができるようにしています15。
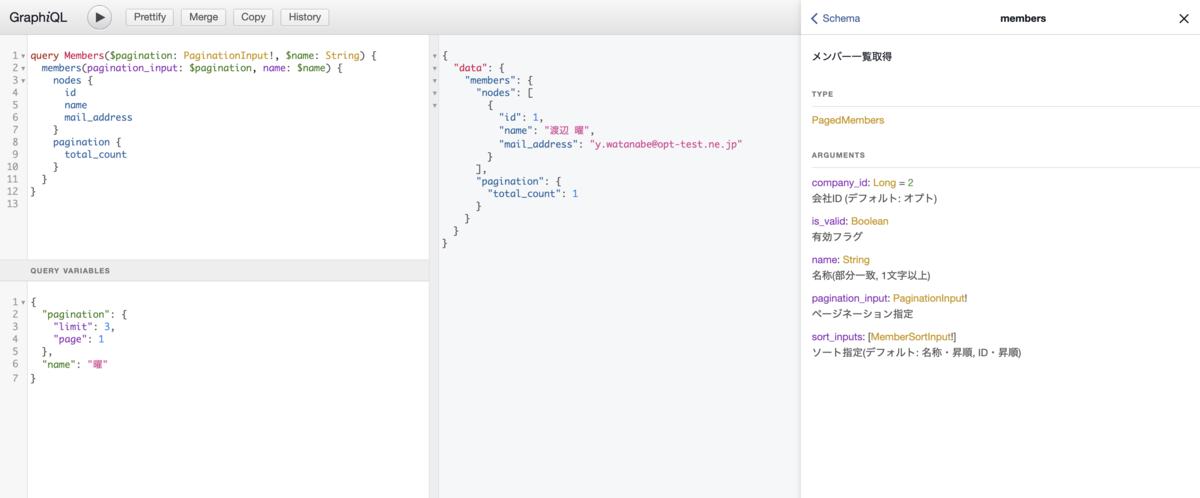
GraphiQLのUIからは、リアルタイムの補完やチェックが効くエディタを介してAPIを呼び出したり、スキーマ定義から生成されたドキュメントを読んだり、クエリをURLで共有したりすることができ、とても便利です。
その他には、社内のAPI利用サービス開発者向けに主要なバックエンド開発言語でのクライアント側サンプルコードやAPIの利用方法を簡潔にまとめたドキュメントも用意しました。
まとめ
以上、広告媒体アカウント管理システム「アムズ」のデータベースを抽象化する社内共有のGraphQL APIをClojureでなぜ、どのように開発してきたか、ご紹介しました。
振り返ってみると、「アムズAPI」を開発するチームが発足した当時の私はClojureとGraphQLという技術を使うこと自体もひとつのモチベーションになっていました。
現在までにClojureを開発言語として利用するプロダクトが複数生まれ、GraphQLについてもこのAPIに続くように複数のプロダクトでGraphQL API開発が始まっています。
2017年にClojure、2019年にGraphQLを初めて正式にプロダクトに導入し、今では会社のマスタデータ基盤として重要な位置を占めるものになりつつあり、システムと組織に良い影響を与えているようであることは、それを進めてきた開発者としてとてもありがたく感じています。
一方で、この約1年の間に私は開発チームをテックリードとしてまとめる立場になり、また、社内システム全体の現状の構造的な課題が明確になるにつれて、将来に向けていかに設計し改善していくべきか考えさせられる機会が多々ありました(Opt Technologiesにとって「アムズAPI」開発はマイクロサービスアーキテクチャへ向けた動きの始まりでした)。
ClojureやGraphQLといった個別の技術の良さを最大限に活かしてプロダクトの価値をさらに高めるのはもちろん、その範囲を超えて会社全体として何を目指し、それを支えるためにどのようなシステムを作り出すのかというアーキテクトとしての観点、開発組織とメンバーをどのように育てるのかというエンジニアリングマネージャーとしての観点の双方から効果的な施策を模索し推進していきたいと考えています。

-
Shibuya.lispはCommon LispやClojureなどLisp系言語使い(Lisper)のための国内最大のコミュニティです。↩
-
もちろんノルマン・コンクエスト(Norman Conquest)と掛けています。↩
-
この名前は"account management system"、略して"AMS"の読みに由来します。↩
-
2019年11月には『初めてのGraphQL』として日本語版も発売されました🉐↩
-
特にLearnのページにはクエリ言語とスキーマ言語の要点が簡潔にまとまっているので早めに一通り読んでおくのがオススメです。↩
-
Opt Technologies公式サイトにあるように、現在の主なバックエンド開発言語はScala, Ruby, PHP, Java, Clojure (順不同)です。↩
-
公式ドキュメントのRationale > Object Orientation is overratedでは(従来型の)オブジェクト指向的な機能や設計はClojureでは採用しないという設計思想が表明されています。↩
-
ちなみに英語のsimpleとsingleは語源的に密接に関係があるとされています(
sim-,sin-にはone, togetherのような意味がある)。↩ -
その後、2020年には新たにバックエンドにGraphQL APIを開発するプロダクトチームが登場し、そこではScala + Sangriaが採用されました。Clojure + Laciniaとはいろいろな意味で差があり、知見の蓄積と相互共有が進んでいます。↩
-
実は直前のコード例に登場している
defresolver(“define resolver"の略)というリゾルバ関数定義構文も、GraphQLライブラリLaciniaの提供機能などではなく私が独自に定義したマクロです。GraphQLのリゾルバ関数で共通して実行したい処理を隠蔽しています。↩ -
後述のテストコード例で
t/から始まるもの(t/deftest,t/testing,t/is)がclojure.testの機能です。↩ -
ClojureではLispらしい開発スタイルとしてREPL駆動開発(REPL-driven development)がごく一般的で、小さな単位でテストコードがなくても任意の単位のコードを動かしながら書き進められることから、開発過程でユニットテストをあまり必要としないという判断もありました。↩
-
GraphiQL用のエンドポイントはLacinia-Pedestalの標準機能で用意できます。↩