BERTの解説記事を英語から翻訳しました。
- 前書き
- 初めに
- 使用例:文章分類
- モデルの構成
- 畳み込みニューラルネットワークとの類似点
- 埋め込みの新時代
- ULMFiT: NLPにおける転移学習の実用性をはっきりさせた
- Transformer: LSTMの先へ
- OpenAI Transformer: language modelingのためにTransformerのDecoderの事前学習
- 下流タスクへの転移学習
- BERT: Decoders から Encoder に
- BERTを使ってみましょう
- 謝礼文
- まとめ
前書き
この記事は、Jay Alammar氏が書いた記事をもとに、日本語に翻訳したものです。できるだけ、ニュアンスを含めて元の内容に沿って書いたつもりですが、翻訳が難しい表現などを含めて、多少の相違点はあるかもしれません。ご了承ください。
原文:「The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)」
作者:Jay Alammar
元の論文:「BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding」
注意:本記事の「前書き」と「まとめ」のセクションは元の記事にはありません。ですので、この二つのセクションの発言は、私(Melvin Charles DY)が文責を負います。
また、画像の一部には日本語で加筆させていただきました。加筆した画像の各自に、元の画像へのリンクが貼ってあります。
初めに
2018年は、テキストを扱う機械学習モデル(もっと正確に言えば、自然言語処理(Natural Language Processing, 略して「NLP」))にとって変曲点でした。言葉や文章を、それらの裏に潜む意味や関係性を捉えて最適な形で表す方法について、概念的な理解が急速に進んでいます。そのうえに、世界中のNLPコミュニティは、自分のモデルやパイプラインにも自由にダウンロードして使える、非常に有力なコンポーネントを続々と公開しています。(NLPにおいてのImageNet momentとも呼ばれ、数年前に似た発展によってコンピュータビジョンのタスクに対する機械学習が加速化したことに言及しています。)

(ULM-FiTは、クッキーモンスターにはまったく関係ありません。だが、ほかに思い当たるものはなかったので…)
この発展の中に、最近の重要な節目といえば、NLPの新時代を切り開く出来事とも描写された、BERTの公開です。BERTは、言語をもとにしたタスクに対する精度の記録のいくつかを破ったモデルです。モデルを解説した論文の公開から間もなく、開発チームがモデルの中核をオープンソース化にして、膨大なデータセットを学習させたモデルの数種類を自由にダウンロードできるようにしました。これは重大な出来事でした。
なぜなら、自然言語に関連するモデルを開発している人の誰もが簡単に入手できるコンポーネントとしてこのモデルを利用することができるようになったことによって、ゼロから自然言語処理モデルを作る場合にかかる時間、労力、知識と、資源を費やさずに済むようになったからです。
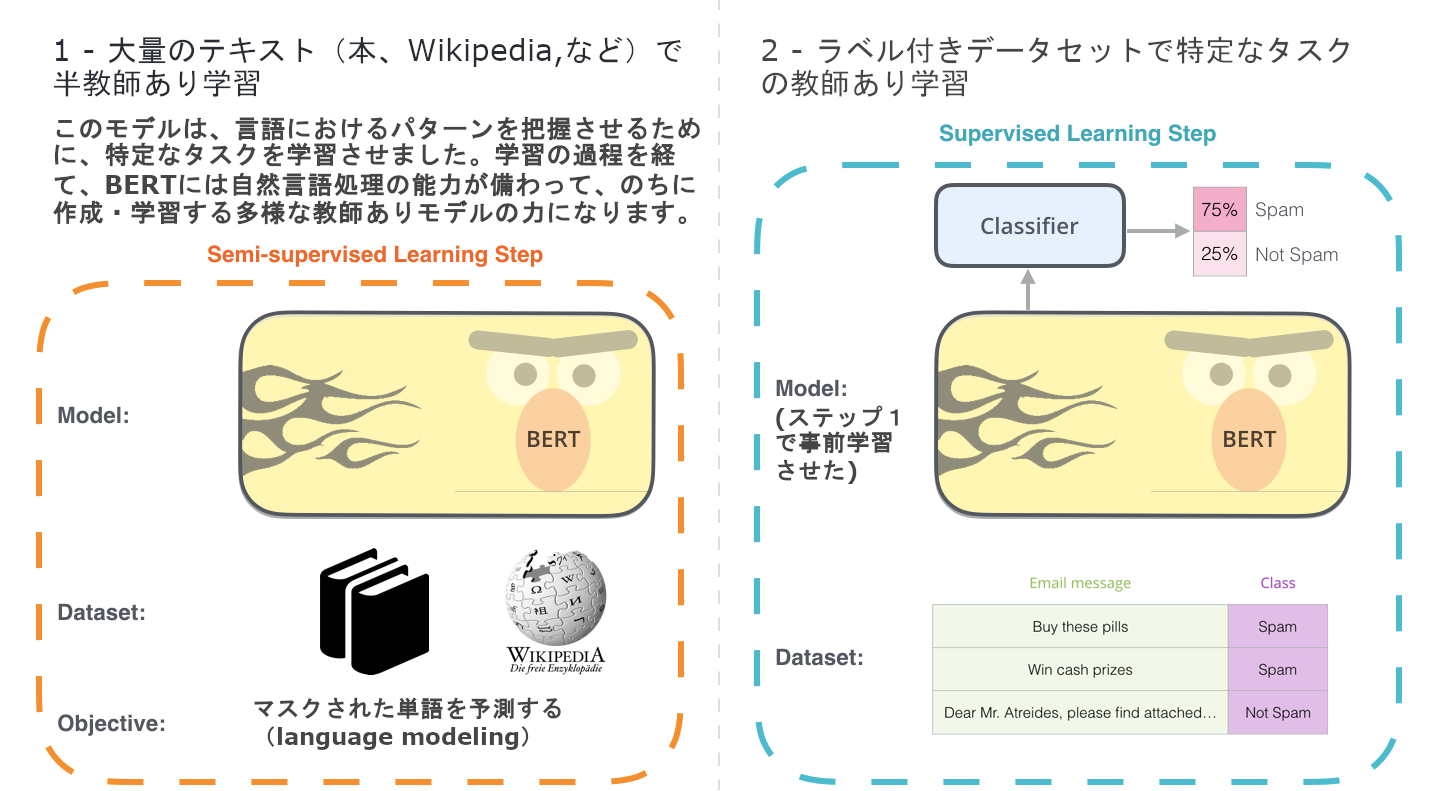
(元の画像)
BERTの開発のための2つのステップ。ステップ1で(ラベルなしのデータで)事前学習させたモデルはダウンロードして、ステップ2におけるfine-tuningだけに注力すれば良いのです。 (本のアイコンの引用元)
{kind=link}
{kind=link}
BERTは、以下に書いたものを含め、最近NLP界隈に湧いてきたいくつかの賢い発想を基に作られたものです。
- Semi-supervised Sequence Learning(Andrew Dai氏とQuoc Le氏)
- ELMo(Matthew Peters氏を含め、AI2とUW CSEの研究者たち)
- ULMFiT(fast.aiの創業者であるJeremy Howard氏、Sebastian Ruder氏)
- OpenAI Transformer(OpenAIの研究者たちである、Radford氏やNarasimhan氏やSalimans氏やSutskever氏)
- Transformer(Vaswani氏等)
BERTを正確に理解するのには、知っておく必要がある概念はいくつかあります。さて、モデルに含まれた概念を見る前に、BERTの使い方を見ていきましょう。
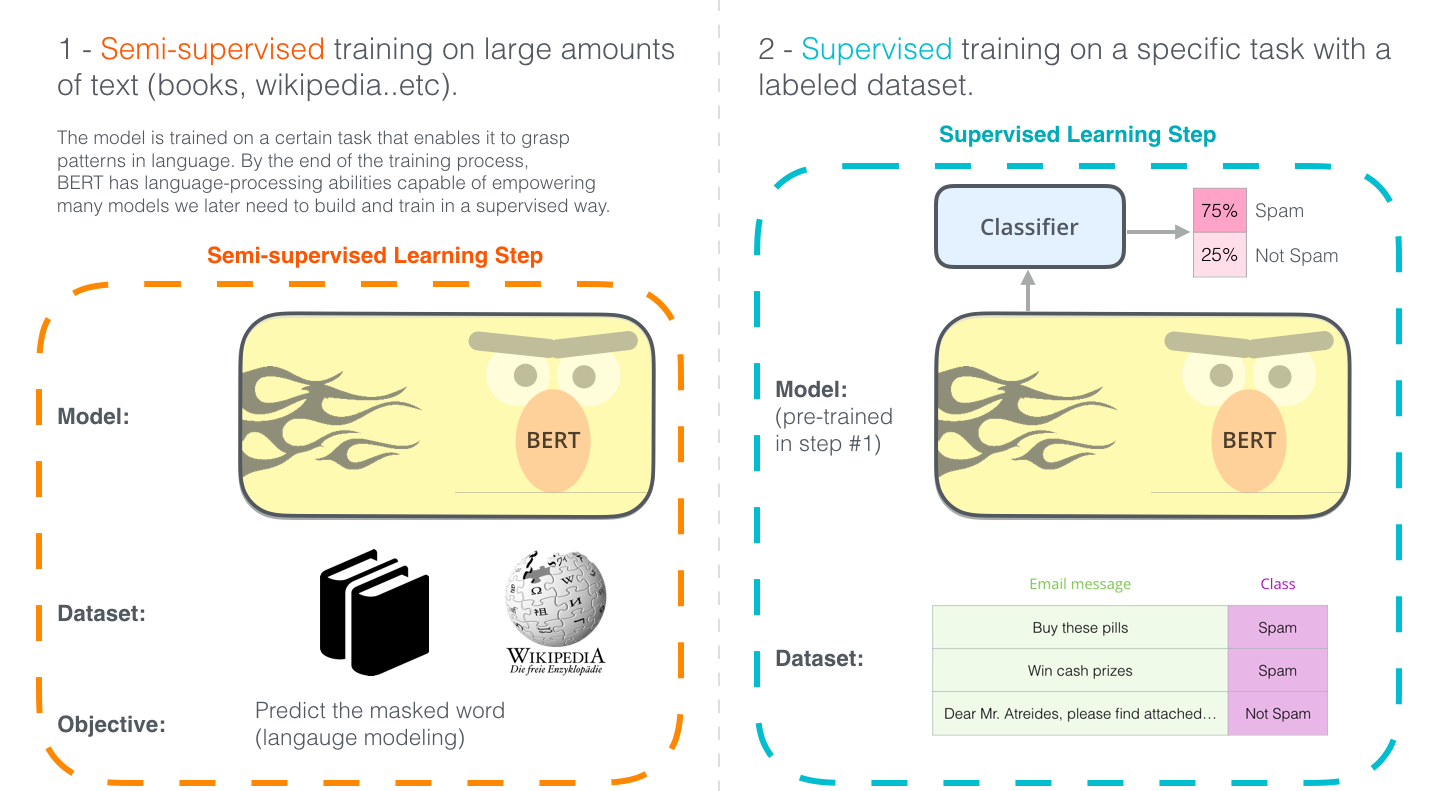
使用例:文章分類
BERTの一番わかりやすい使い方といえば、一つの文章の分類に使うことです。モデルは次のようになります。

このようなモデルを学習させるのには、学習させる必要があるのは主に分類器のほうで、BERTモデルにおいての変化はごく少ないです。このプロセスは「fine-tuning」と呼ばれ、Semi-supervised Sequence LearningとULMFitに由来したものです。
このトピックに詳しくない人もいると思いますので、分類器について話をしており、私たちは機械学習領域の中の教師あり学習分野にいます。つまり、このようなモデルを学習させるためにはラベル付きデータセットが必須です。このスパムメール分類器の例では、ラベル付きデータセットはメールの本文のリストとラベル(文章につきSpamまたはNot Spam)になります。

似たユースケースの例:
- 感情分析
- インプット:映画や商品のレビュー。アウトプット:このレビューはポジティブなのかネガティブなのか。
- データセットの例:SST
- ファクトチェック
- インプット:文章。アウトプット:「主張」か「主張ではない」
- もっと意欲的・未来的な例:
- インプット:主張の文章。アウトプット:「真実」か「虚偽」
- Full Factは、公衆のために自動化されたファクトチェックのツールを開発している組織です。彼らのパイプラインの一部は、ニュース記事中の主張を検知する(文章を「主張」か「主張ではない」に分類する)分類器で、その結果は後程にファクトチェックされます(現在は人間がしていますが、将来的には機械学習で、と望んでいます。)
- 動画:自動化されたファクトチェックのための文章埋め込み - Leo Konstantinovskiy
モデルの構成
BERTの使用方法のユースケースを認識できたと思いますので、どのように動作するのかを詳しく見ていきましょう。

元の論文には、2つのサイズのモデルがありました:
- BERT BASE -- パフォーマンスを比較するために、OpenAIのTransformerと同じスケールのもの
- BERT LARGE -- 論文に報告された現状最高水準の結果を達成できた途方もなく大きいモデル
BERTは基本的に学習させたtransformer-encoderの積み重ねです。せっかく良い機会ですので、私が前に書いた記事The Illustrated Transformerをご一読ください。BERTの基礎的なコンセプトで今後の話にも登場する「Transformer」のモデルをその記事で解説しました。

両サイズのモデルにはたくさんのencoderレイヤー(論文には「Transformer ブロック」と呼ばれた)があります。BASEバージョンには12個で、LARGEバージョンには24個です。両方も、最初の論文に記載された実装例(6 encoderレイヤー、512隠れユニット、8アテンションヘッド)に比べて、より大きいfeedforward network(それぞれ768と1024隠れユニット)と、より多くのアテンションヘッド(それぞれ12と16)を持っています。
モデルのインプット

理由は後程明らかになりますが、最初にインプットされるトークンは特別な[CLS]トークンです。ここにおいて、CLS は Classification(分類)の意味をします。
通常のTransformerのencoderと同じように、BERTは単語の系列を受け付けて、積み重なったレイヤーを通して上に流します。各レイヤーはself-attentionを適用し、結果をfeedforward networkに通してから、次のencoderに渡します。

構成的には、ここまではTransformerと同一です(サイズはさておき…変更できる設定ですし)。モデルの出力部分から初めてTransformerとの違いを見る事ができます。
モデルのアウトプット
各ポジションは hidden_size(BERT Baseでは768)の大きさのベクトルを出力します。上記の文章分類の例の場合、1個目のポジション(特別な[CLS]トークンを入力した箇所)のアウトプットのみを見ます。

そのベクトルは任意の分類器のインプットとして使用できます。論文ではただの単層のニューラルネットワークを分類器に使ったが、とても良い結果を達成しています。
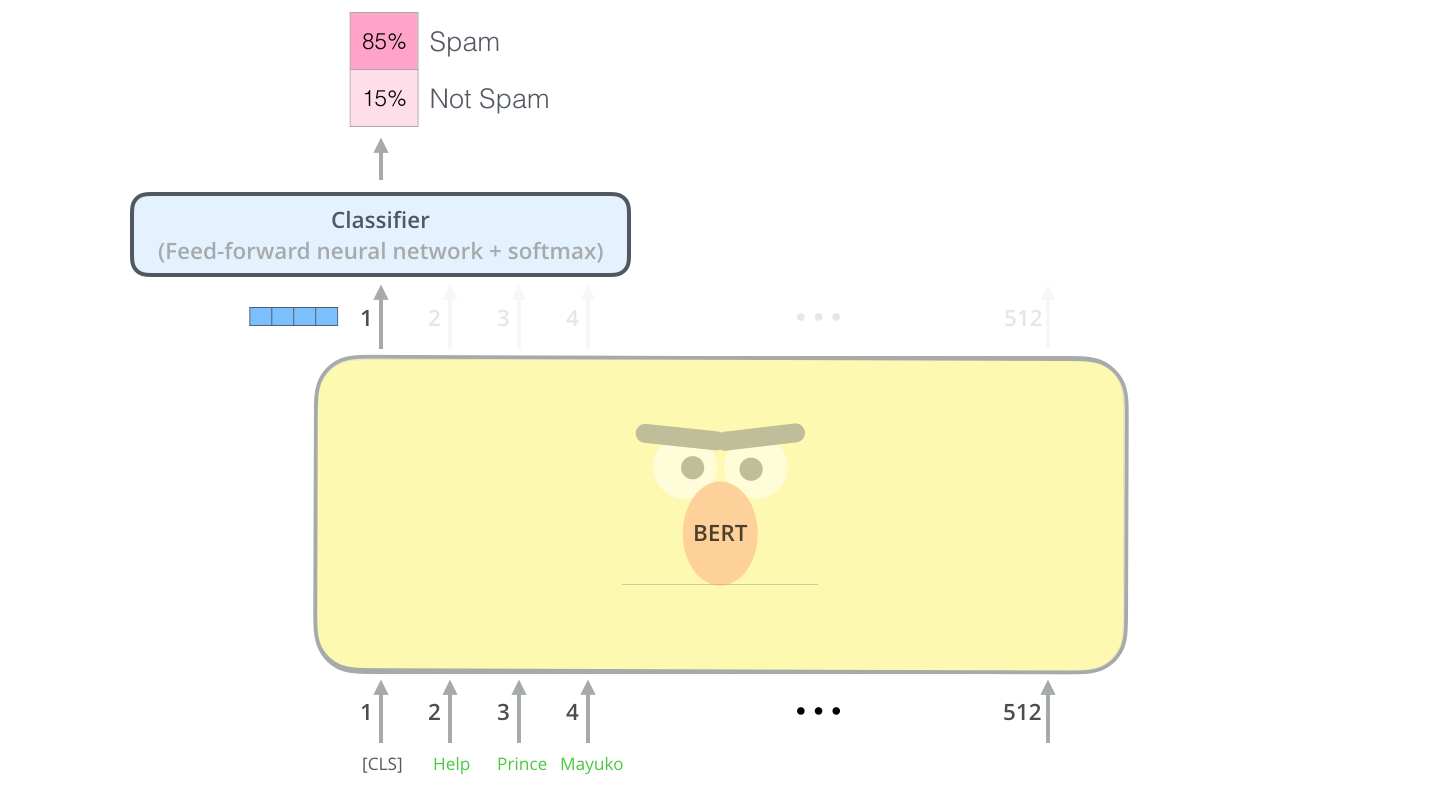
複数のラベルを使用する場合(spam、not spam、social、promotionでタグ付けをするメールサービスなど)も、出力のニューロンを増やすように分類器に変更を加えた上で各々softmaxに通すことで可能です。
畳み込みニューラルネットワークとの類似点
コンピュータビジョンの知識を持っている方にとって、このベクトルの受け渡しは、VGGNetのようなネットワークの折りたたみ計算部分とネットワークの最後にある全結合された分類部分の間に起こることを連想させます。

埋め込みの新時代
この新しい進展につれて、単語のエンコーディングに新しい転換が起きています。今までは、先端に立つNLPのモデルがどうやって言語を処理するのかは、単語埋め込みに大きく左右されていました。Word2VecやGloVeのようなメソッドはそのタスクに対して広く使われていました。変更点を見る前に、それらの使い道を軽く復習しましょう。
単語埋め込みの要約
単語が機械学習モデルに処理されるためには、モデルの計算に使える数値表現が必須になります。意味論での関係性(類似しているか、反対しているか、それとも「ストックホルム」と「スウェーデン」のペアに「カイロ」と「エジプト」という言葉の間にある関係性があるのか)や統語論・文法的な関係性(例:「had」と「has」の間の関係性は「was」と「is」の間の関係性と同じであること)が捉えられる単語の表現がベクトル(数字のリスト)を用いて正確にできることは、Word2Vecで実証されました。
小さなデータセットでモデルと同時に埋め込みを学習させるより、大量のデータセットで事前に学習させた埋め込みを使ったほうが良い、ということはすぐに業界内に周知されました。それで、Word2VecやGloVeの事前学習から生成した単語と埋め込みのリストがダウンロードできるようになりました。こちらは、「stick」という単語のGloVe埋め込み(埋め込みベクトルのサイズが200)の一例です:

「stick」の単語埋め込み。200個の浮動小数点数のベクトル(小数点第2位まで四捨五入されました)。200個の値の連続です。
これらは大きく、数字ばっかりなので、私の記事の中にある図などでは、次のシンプルな図形でベクトルを表します。

ELMo: 文脈は重要
上記のGloVe埋め込みを使っていれば、文脈にかかわらず同じベクトルに変換されます。そこで、何人かのNLP研究者たち(Peters氏等, 2017、McCann氏等, 2017、またPeters氏等, 2018のELMo論文に)が言い出しました。
ーー「ちょっと待って、"stick"はどこに使われたのかによって複数の意味合いを持っています。では、そのコンテキストでの意味もそのほかの文脈などの情報も捕捉するように、文脈に基づいて埋め込みを作ればどうでしょうか?」
それで、文脈化された単語埋め込みが誕生しました。

(元の画像)
文脈に当てはめた単語埋め込みを使えば、文章の意味によって違う埋め込みを単語に与えることができます。
また、Robin Williams氏の冥福を祈ります。
{kind=link}
単語ごとの固定の埋め込みを使うより、ELMoは文章の全体を見てから文章内の単語ごとの埋め込みを与えます。埋め込みを生成するのには、特定のタスクに学習させた双方向LSTMを使っています。

ELMoはNLP分野における事前学習への前進に重大な一歩をくれました。ELMoのLSTMは対象問題の言語と同じ言語の大規模なデータセットに学習を経て、言語を扱う必要があるモデルのコンポーネントとして使えるようになります。
ELMoの秘密は何でしょうか?
ELMoは、language modeling(language modeling)というタスク、すなわち単語のシークエンスの中の次の単語を予測するタスクに学習させられ、言語の理解を得ました。ラベルを必要としないから、すでにある大量のテキストデータを学習させられるので、便利です。
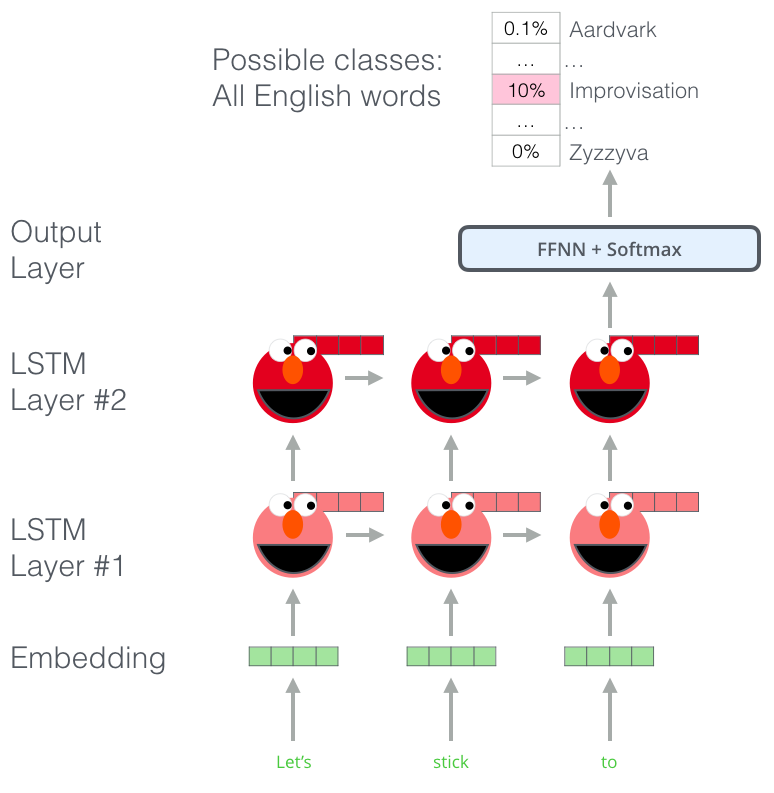
ELMoの事前学習におけるステップ:"Let's stick to"がインプットされた場合、一番可能性が高く次に来る単語を予測する、というlanguage modelingのタスクです。大きいデータセットに学習させられたら、モデルが言語におけるパターンを覚え始めます。この例の場合、次の単語が正しく予測される可能性は低いです。もっと現実的に、"hang"という単語の後に、"camera"とかより("hang out"の)"out"にもっと高い確率を与えます。
図のELMoくんの頭の後ろからちらっと見えるのはunrolled LSTMのステップごとの隠れ状態(隠れユニットの全体)です。事前学習の後に、埋め込み処理に役立ちます。
ELMoは実は、もう一歩前進をして双方向LSTMを学習させるので、言語のモデルに次の単語の意味的な感覚のみとならず、前の単語の意味的な感覚も備えています。

ELMoについてのとても良いプレゼン
ELMoは、特定のやり方(結合してから加重総和算)で隠れ状態(と最初の埋め込み)を組み合わせて、文脈化された単語埋め込みを作ります。

(元の画像)
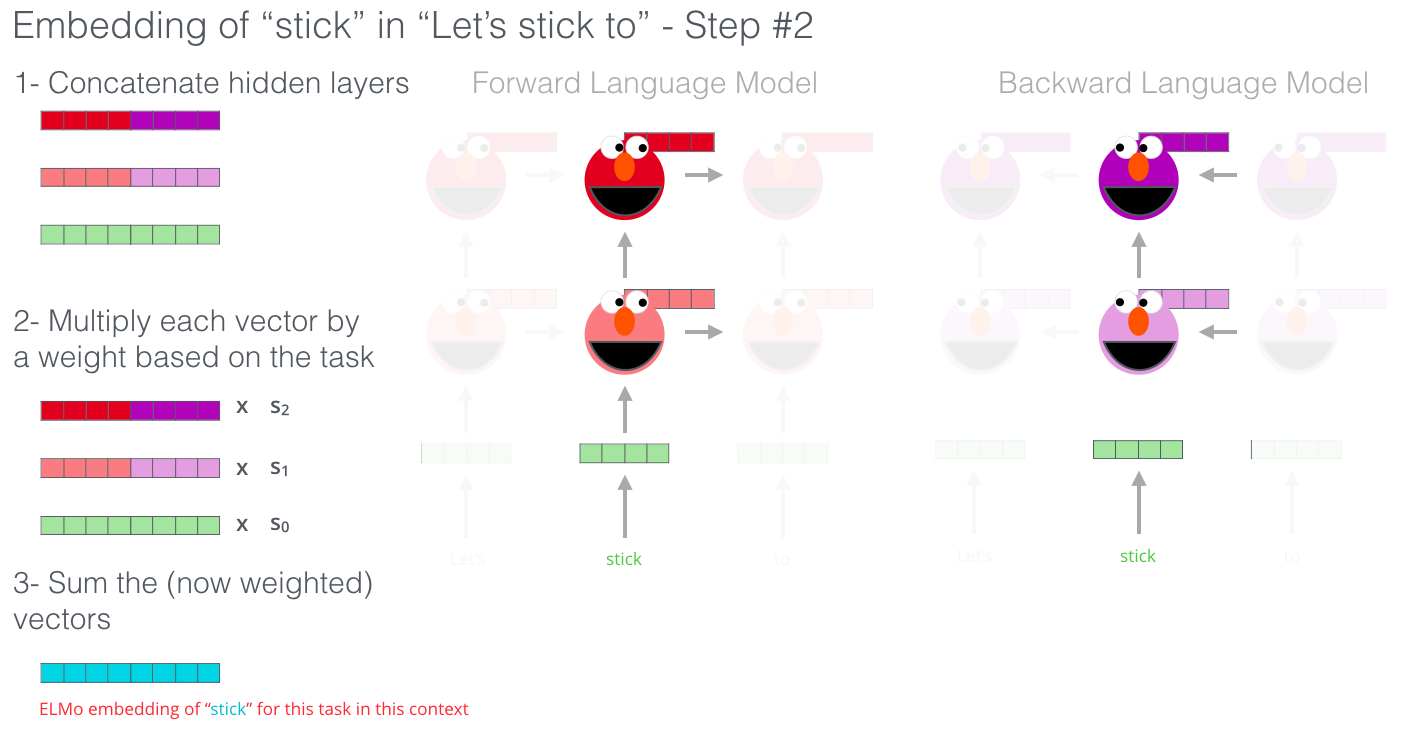{kind=link}
ULMFiT: NLPにおける転移学習の実用性をはっきりさせた
ULMFiTでは、単なる単語埋め込みや文脈化された単語埋め込みに留まらず、モデルが事前学習で学んだもののほとんどを効果的に使用できるように、いくつかの手法を導入しました。ULMFiTにより、言語モデルと、その言語モデルを様々のタスクに合わせるための効果的なfine-tuningの手順が紹介されました。
コンピュータビジョンと匹敵できる転移学習のやり方は、やっとNLPの手に入りました。
Transformer: LSTMの先へ
Transformerの論文とソースコードの公開、そして機械翻訳に成せた結果から見ると、LSTMの代替品として使えるのではないかと思われるようになりました。Transformerは長期の依存関係をLSTMよりうまく扱えることもあり、その意見が強くなりました。
Transformerのencoder-decoder構成は、機械翻訳にうってつけです。ですが、どうすれば文章分類に使えるのでしょうか?どのように使用すれば他のタスクのためにfine-tuningできる言語モデルが事前学習できるのでしょうか?(業界内、事前学習されたモデルやコンポーネントを使う教師あり学習タスクは「下流タスク」と呼びます。)
OpenAI Transformer: language modelingのためにTransformerのDecoderの事前学習
実は、自然言語処理タスクに転移学習とfine-tuning可能な言語モデルを応用するのに1つのTransformer全体は必要ないことが明らかになりました。Transformerのdecoder部分だけで十分です。ここでdecoderが良い選択肢である理由は、将来のトークンをマスクするように作られたことが単語一つずつでの翻訳生成には貴重な機能であり、language modeling(次の単語を予測すること)にピッタリだからです。

OpenAI TransformerはTransformerのdecoder部分の積み重ねで構成されています。
モデルでは12層のdecoderレイヤーを積み重ねています。この構成にはencoderがないので、通常のTransformer decoderレイヤーが持っているencoder-decoderアテンションのサブレイヤーはありません。ただし、(将来のトークンを覗かないようにマスクされている)self-attentionレイヤーは通常通りにあります。
この構成で、大量の(教師なし)データセットで次の単語を予測する、という同じlanguage modelingタスクの学習は進められます。7000冊の書籍を投げ込んで学習してもらえば良いのです!このようなタスクに書籍が適しているのは、大量のテキストで区切られていても関連性のある情報を紐付けることができるためです。記事やツイートなどで学習している場合には起きない現象です。

これで、OpenAI Transformerは7000冊の書籍から作られたデータセットで次の単語を予測するように学習するのに準備が整いました。
下流タスクへの転移学習
OpenAI Transformerが事前学習によってレイヤーが言語を適切に扱うように調整されたことにより、下流タスクに使えるようになりました。まずは、文章の分類(メールをspamとnot spamに分類すること)を見ましょう。

事前学習されたOpenAI Transformerを用いた文章分類のしかた
OpenAIの論文では、いくつかのタスクの入力を扱うための入力変換が概説されています。次の画像は論文から引用したもので、いくつかのタスクを実行するためのモデルの構成と入力変換を示しています。

賢くないですか?
BERT: Decoders から Encoder に
OpenAI Transformerによって、Transformerをベースにしたfine-tuning可能な事前学習モデルができました。しかし、このLSTMからTransformerへの変遷には何かを失いました。ELMoの言語モデルは双方向でしたが、OpenAI Transformerは前向言語モデルのみを学習しています。Transformerをベースにした、前方も後方も見ている(専門用語では、「左と右のコンテキスト両方に調節された」)言語モデルは作れるのでしょうか?
年齢制限指定のBERT:「俺のビールを持っててくれ。」
マスクされた言語モデル
BERT:「Transformer encoderを使おう。」
Ernie:「それは狂気の沙汰だ。双方向の調節によって、複数層コンテキストの中に各単語が間接的に自分が見えるようになるって、みんな知っている。」
BERT:(自信満々)「マスクを使うのだ。」

(元の画像)
BERTの賢いlanguage modelingタスクは、入力の単語の15%をマスクし、モデルに欠けた単語を予測してもらうのです。
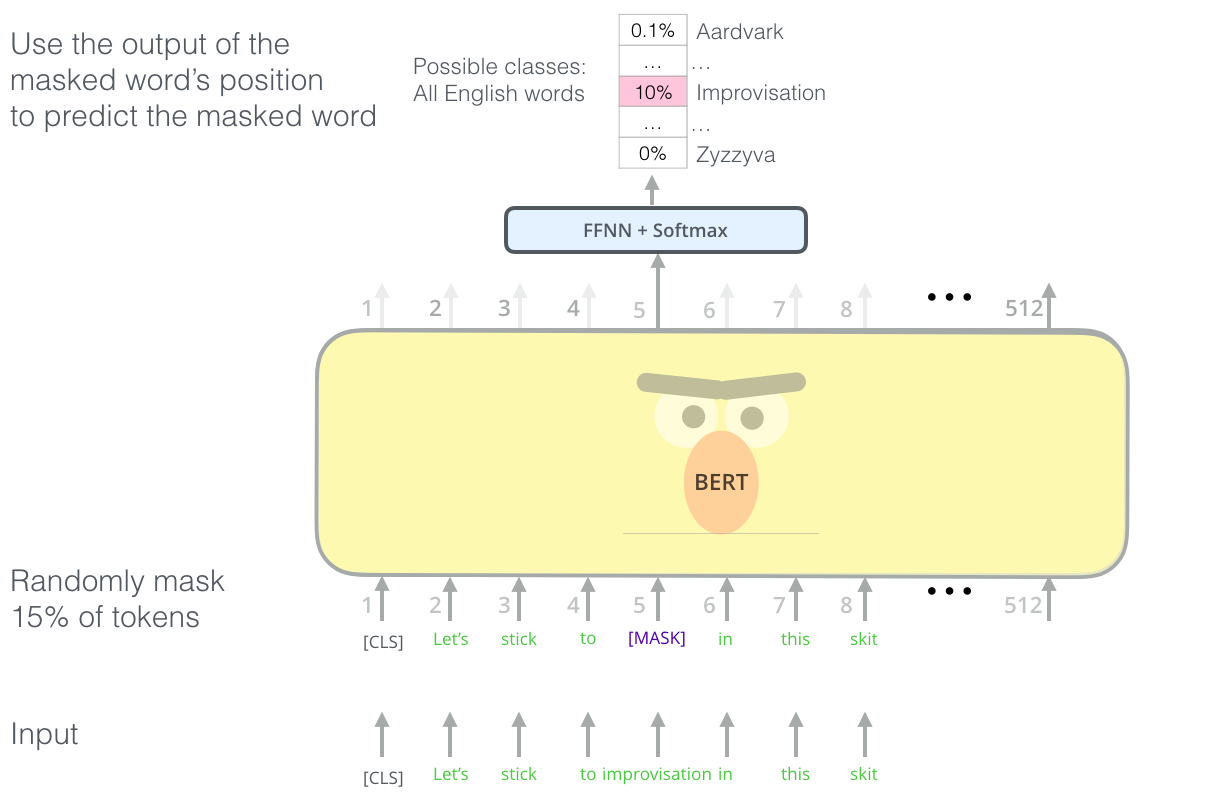{kind=link}
Transformer decoderの積み重ねを学習させられる正しいタスクを見つけるのは複雑なハードルで、BERTは「マスクされた言語モデル」という概要(「Cloze task」とも呼ばれる)を既存研究から応用して解決しました。
入力の15%をマスクするだけでなく、fine-tuningでのモデルの性能向上のために少しだけ混ぜ合わせています。すなわち、時折マスクする代わりにランダムな別の単語に置き換え、モデルにその位置の正しい単語を予測させるのです。
ツーセンテンスタスク (Two-sentence Tasks)
OpenAI Transformerが様々なタスクを処理するために実施している入力変換を読み返すと、いくつかのタスクでは2つの文について何らかの知的なことを述べることがモデルに要求されていることがわかります。(例えば、お互いはただの言い換えですか? Wikipediaのエントリとそれに対する質問を入力として、質問に答えることはできますか?)
BERTにおいて複数のセンテンスの間の関係性の処理を向上させるために事前学習には、2つの文(A, B)についてBがAに続く文かどうかを推定するという、もう一つのタスクが含まれます。

(元の画像)
BERTが事前学習させられた二つ目のタスクは2文間の分類タスクです。この画像に描写したトークン化は単純化しすぎています。BERTは単語ではなく、WordPieceを使っているのでいくつかの単語はもっと小さいかけらに分解されます。
{kind=link}
タスク特化モデル
BERTの論文では異なるタスクにBERTを適用するいくつかの方法を紹介しています。

特徴点抽出のためのBERT
BERTの使い方はfine-tuningのアプローチだけではありません。ELMoと同様に、事前学習されたBERTを使って文脈化された単語埋め込みを作成することはできます。その後、埋め込みを既存のモデルに流し込めば良いのです。この過程は、固有表現抽出のようなタスクでBERTをfine-tuningした場合の結果と比べてさほど落ちていない、と論文が示した。
 (元の画像)
(元の画像)
文脈化された単語埋め込みにはどのベクトルが最適ですか?タスクによると思います。論文では6つの選択肢を調査しています(96.4のスコアを達成したfine-tuningされたモデルと比較した):
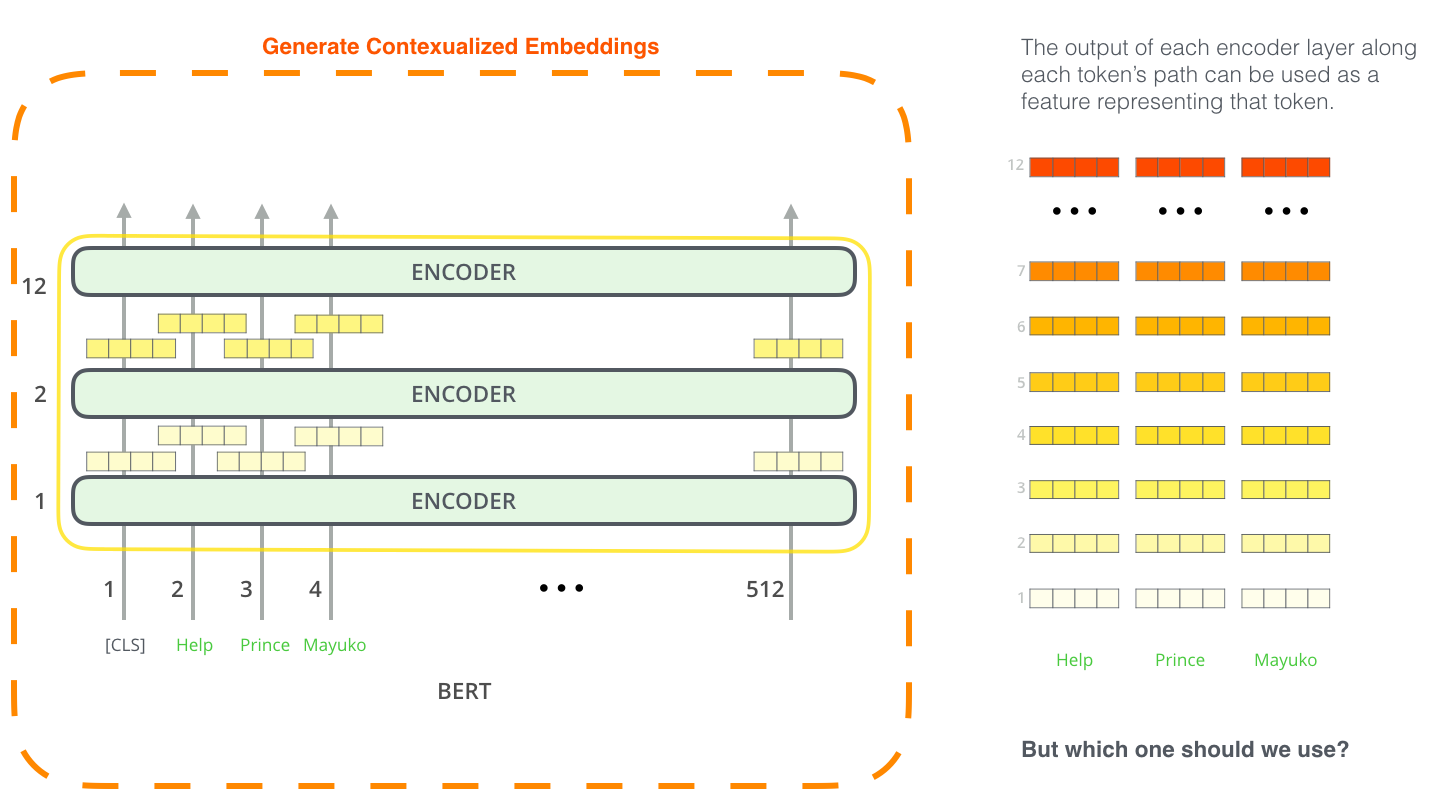{kind=link}

(元の画像)
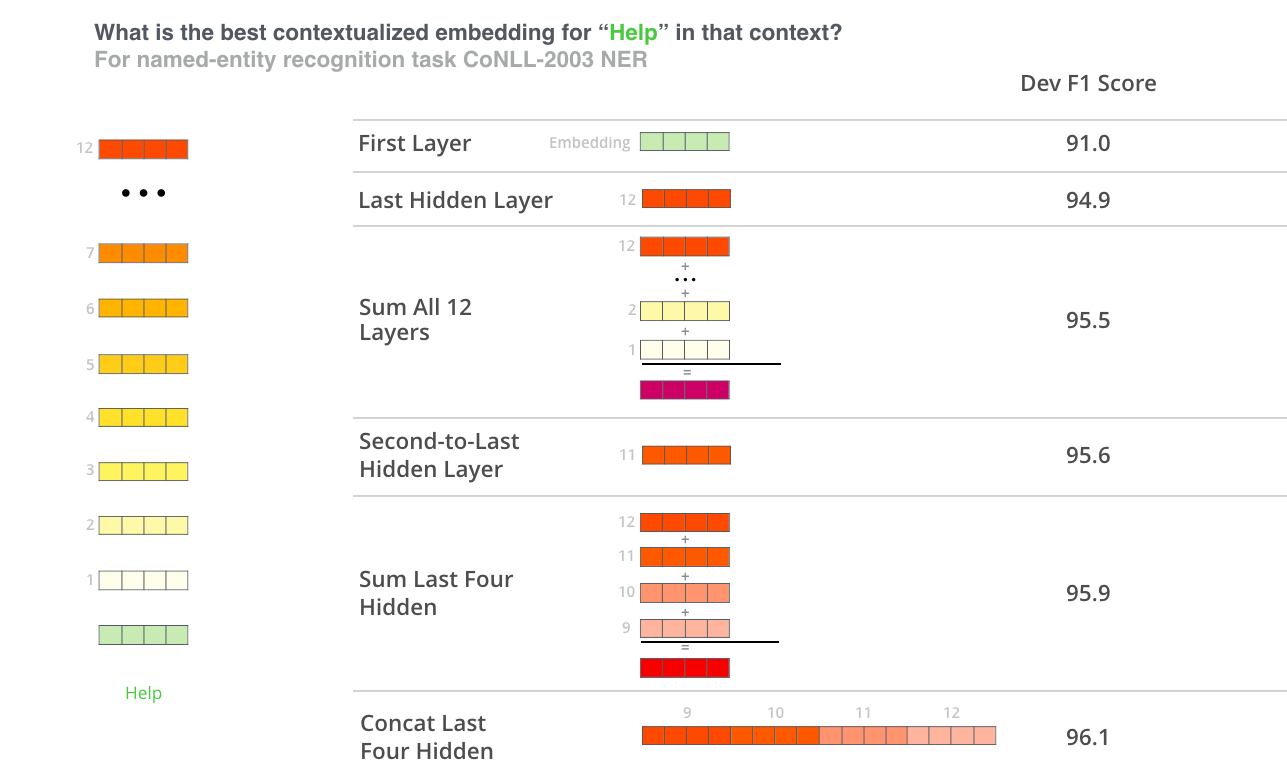{kind=link}
BERTを使ってみましょう
BERTを試す一番良い方法はGoogle Colabで公開されているBERT FineTuning with Cloud TPUsです。BERTのコードはTPU・CPU・GPUのいずれにも実行できるので、クラウドTPUを使ったことがなければ、これはちょうど良い機会です。
次のステップは、BERTのリポジトリにあるコードを見ることです。
- モデルはmodeling.py(class BertModel)で構成さていて、通常のTransformer encoderとほとんど一緒です。
- run_classifier.pyはfine-tuning過程の一例です。教師ありモデルの分類レイヤーも構成しています。自分の分類器を作成したい場合は、そのファイルの中のcreate_model()関数を見てください。
- いくつかの事前学習モデルはダウンロードできるようになっています。BERT BaseやBERT Largeの他に、英語や中国語などの言語、およびWikipediaで学習させた102言語を対象とした多言語モデルも存在します。
- BERTは単語をトークンとしてみません。むしろ、WordPieceを見ています。tokenization.pyは、単語をBERTに相応しいWordPieceに変換してくれるトークナイザーです。
BERTのPyTorch実装を見るのも良いでしょう。AllenNLPではこの実装を用いてBERT埋め込みを任意のモデルで使用できるようにしています。
謝礼文
Jacob Devlin氏、Matt Gardner氏、Kenton Lee氏、 Mark Neumann氏、 と Matthew Peters氏に、本投稿の草稿についてのフィードバックをくれたことに感謝を申します。
2018年12月3日に記述しました。
まとめ
BERTはOpenAI Transformerのencoder部分を積み重ねたうえで、入力の15%をランダムにマスクして学習させたものです。膨大なデータセットを使ってゼロから学習させる必要はなく、事前学習モデルをダウンロードすれば、様々なニーズに適用できます。ぜひ、使ってみてください。

この 内容 は クリエイティブ・コモンズ 表示 - 非営利 - 継承 4.0 国際 ライセンスの下に提供されています。
Opt Technologiesに興味のある方は、こちらから「カジュアル面談希望」と添えてご応募ください!
